Visual Retrievers
October 27, 2025
Have some experience working with VLMs, and it got me thinking about retriever systems using vision instead of text. So I did some digging and it lead to this post
My initial hypothesis was that visual systems should overtake text-only alternatives for real world applications. Documents are messy, real-world systems operate on PDFs, slides, and scanned images filled with charts and complex layouts, not clean text files. As Jo points out however there are still domains where formats are not complex and converting to text is possible with high accuracy.
The standard approach—brittle parsing pipelines—discards all visual information and often mangles the text structure. The alternative, classic dual-encoders like CLIP or SigLIP, are optimized for natural image-caption matching and fail to deeply parse embedded text. The new approach uses generative VLMs as the retrieval backbone, operating directly on raw page images and bypassing parsing entirely.
From bi-encoders to late interaction
To see why VLMs are impactful here, it helps to have a mental model of neural matching. The 2020 ColBERT paper is a good anchor for the main paradigms.
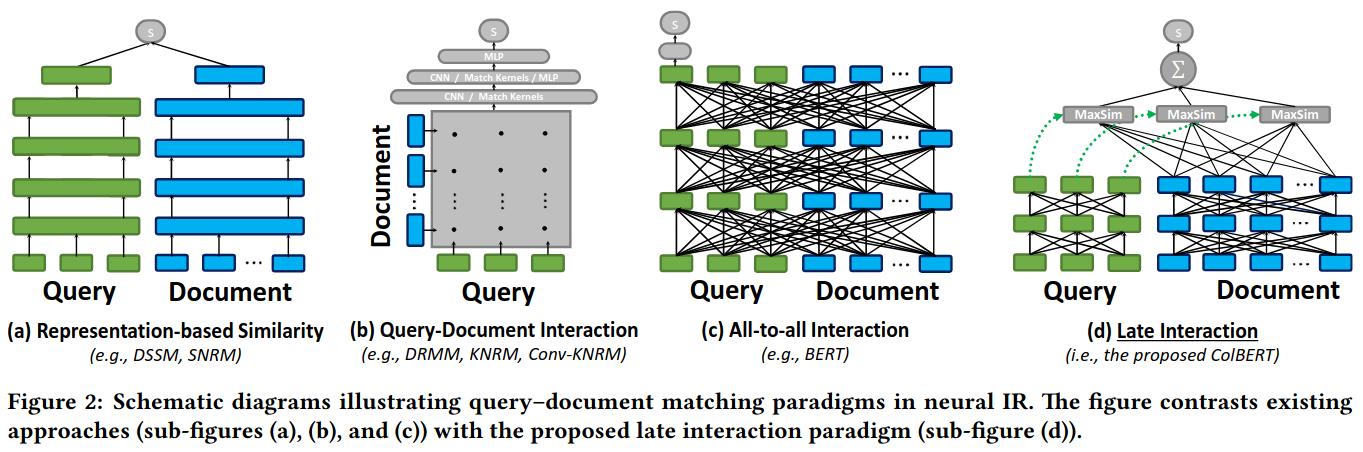
First are representation-based models (bi-encoders), which map a query and document into independent, single-vector embeddings. Relevance is just a similarity score (e.g., cosine similarity) between them. This remains the most popular approach because it's fast: you pre-compute all document embeddings offline and use a vector index for fast approximate nearest-neighbor (ANN) search.
On the other end of the spectrum are interaction-based models (cross-encoders). These concatenate and into a single sequence and feed them through a large model (like BERT), allowing full, deep attention between every query and document token. Unsurprisingly, this is far more accurate but computationally brutal. You can't pre-compute anything; you must run a full encoding pass for every query-document pair, making it infeasible for first-stage retrieval (it's a common re-ranker).
ColBERT introduced a brilliant compromise: late interaction. Like a bi-encoder, it embeds and separately. But instead of a single vector, it creates a multi-vector representation—a bag of contextualized embeddings for each token. The relevance score is then computed as the sum of maximum similarities (MaxSim) between each query embedding and all document embeddings. This approach provides the best of both worlds: the efficiency of pre-computing document representations offline, combined with the accuracy of fine-grained, token-level interactions. This late-interaction paradigm is what underpins most modern SOTA visual retrievers.
ColPali
The ColBERT paradigm, however, still assumes you have text. The big leap was applying this late-interaction model to images of documents. ColPali was one of the first major works to do this. The idea is simple: treat document pages as "screenshots."
Instead of parsing, you feed the raw page image into a VLM (like PaliGemma, which pairs a SigLIP vision encoder with a Gemma LM). The VLM processes the image, splitting it into patches that are fed to the vision transformer. These patch embeddings are then projected and treated as "soft tokens" by the language model. The output is a set of high-quality, contextualized patch embeddings in the LM's space. ColPali projects these down (e.g., to ) and stores them as a multi-vector representation for each page image. This is exactly the ColBERT model, but operating on visual patches instead of text tokens. It completely bypasses OCR.
Findings in visual retrieval
Using generative VLMs as retrieval backbones is a new field, and it's forcing a re-evaluation of core assumptions. The recent ModernVBERT paper ran a fantastic set of ablations that highlight the key design choices.
Bidirectional vs. Causal Attention. The most important question is architectural. VLMs are typically decoders, trained with a causal (next-token prediction) attention mask, which is great for generation. Retrieval, conversely, has almost always favored encoders (like BERT) with bidirectional attention, trained on objectives like Masked Language Modeling (MLM). ModernVBERT compared two models with identical architectures, data, and size, differing only in their attention mask and pre-training objective (CLM vs. MLM). The results were stark: on the ViDoRE benchmark (the standard for visually-rich document retrieval), the bidirectional encoder substantially outperformed the causal decoder in all late-interaction setups. This finding led to ColModernVBERT, a compact retriever (150M text encoder + 100M vision encoder) built with bidirectional attention. It punches way above its weight, rivaling the 3B-parameter ColPali. This suggests that for retrieval, using the right inductive bias (bidirectional attention) is far more important than just scaling up a generative (causal) one.
Closing the Modality Gap. Another key insight, highlighted by Jina-v4, relates to why VLMs are so much better at this than older CLIP-style dual encoders. Dual-tower models often suffer from a "modality gap": the text embeddings and image embeddings live in structurally different parts of the embedding space. A good text-text match will have a much higher similarity score than an equally good text-image match. VLMs, by contrast, force both visual "soft tokens" and text tokens through a single, unified language model. Jina-v4 (built on the Qwen2.5-VL backbone) shows this creates a much more tightly aligned shared semantic space, dramatically reducing the modality gap and enabling more effective cross-modal retrieval.
Data and Training Strategies. This field still suffers from a severe lack of high-quality, visually-rich document-query data. To compensate, interesting training strategies have emerged. The ModernVBERT team found that cross-modal transfer—interleaving abundant text-only document-query pairs with text-image pairs during training—improved performance on the visual-only task. NVIDIA's NemoRetriever models (a 1B and 3B family) use staged training. First, they train a strong text-only retrieval model (bidirectional attention, contrastive loss). Only then do they introduce the visual modality and fine-tune on text-image pairs, establishing a strong semantic foundation before adding visual complexity.
Cost trade-offs
This brings us to the sobering reality: storage costs. Late interaction comes at a massive cost. A single-vector bi-encoder stores one vector per document. A late-interaction model stores one vector per token (or patch). The NemoRetriever paper lays this out: their 3B model (embedding , average sequence length 1802 tokens) requires 10.3 TB of storage for just 1 million images. This is orders of magnitude larger than a single-vector approach.
While studies like ModernVBERT note that inference latency is often bottlenecked by query embedding time (which scales with model size) rather than the late-interaction matching, the storage cost is frequently a non-starter.
This leads to the most pragmatic, real-world architecture: the retrieval cascade. This typically involves two stages. Stage 1 (Recall) uses a cheap, fast bi-encoder (single-vector) to retrieve a large candidate set (e.g., ) from the full corpus, optimizing for high recall at low cost. Stage 2 (Precision) then uses a powerful, expensive model—like a late-interaction ColPali/ColModernVBERT or even a full cross-encoder—to re-rank only those 100 candidates, optimizing for high precision. The NemoRetriever team found this bi-encoder + re-ranker setup offered a far better performance-cost trade-off than a pure late-interaction system, albeit with a small latency hit from the re-ranking step.
Concluding thoughts
Using VLM backbones for document retrieval is clearly a promising path, especially for any use case where parsing clean text is hard (which is... most of them). The ability to operate on raw pixels, capturing both text and layout, is a huge unlock.
The field is still new, and the central challenge is the tension between the accuracy of late interaction and the storage/latency costs of single-vector bi-encoders. The cascade approach seems like the most practical solution today.
I'm particularly interested in the why behind this. The DeepSeek OCR paper, for instance, showed that VLMs can achieve massive visual text compression—recovering text with 98% accuracy using 10x fewer visual tokens than raw text tokens. This implies the VLM's internal representations of visual text and tokenized text are becoming highly aligned. How deep does this alignment go? Can we observe it in the hidden states? Understanding this relationship seems key to building more efficient and powerful visual retrievers.