DeepSeek OCR
Original paper · Wei et al 2025
Rushed notes from reading the DeepSeek OCR paper.
The quadratic scaling of attention in LLMs remains a primary bottleneck for processing long contexts. DeepSeek (interns?) investigate a novel approach to this problem: contexts optical compression. The core idea is to leverage the visual modality as an efficient compression medium for text. Instead of processing a long sequence of text tokens, the text is first rendered into a 2D image, which is then processed by a VLM.
OCR provides an ideal testbed for this compression-decompression paradigm, offering a clear, natural mapping between the visual representation and the original text, complete with quantitative evaluation metrics. The paper's headline claim is that this method can achieve a ~10x compression ratio (text tokens to vision tokens) while maintaining ~97% decoding precision. Even at 20x compression, accuracy is reportedly ~60%.
This entire paradigm, however, is contingent on the VLM's vision encoder. To be viable, the encoder must efficiently process extremely high-resolution, text-dense images and output a manageable number of vision tokens, all while maintaining low activation memory. The paper notes that existing open-source encoders can't fully satisfy all these conditions, which motivates their focus on a novel architecture. This specific set of constraints makes it useful to review the current landscape.
Vision Encoders
Here’s a recap on the state of vision encoders.
Vision Encoders are responsible for encoding the visual input to VLMs, often with some ViT architecture. However, handling dynamic, or native input resolution isn't supported in vanilla ViTs, so VLMs adopt techniques to get around this. The core architectural challenge is adapting standard ViTs for high-resolution, variable-aspect-ratio inputs. Most ViTs are pre-trained with fixed-resolution inputs, a suboptimal convention that forces a trade-off: either downsample the image, losing significant detail, or pad the image, which is computationally inefficient.
To process real-world data like documents—which are both high-resolution and have extreme aspect ratios—two primary strategies have emerged: tiling and adaptive resolution.
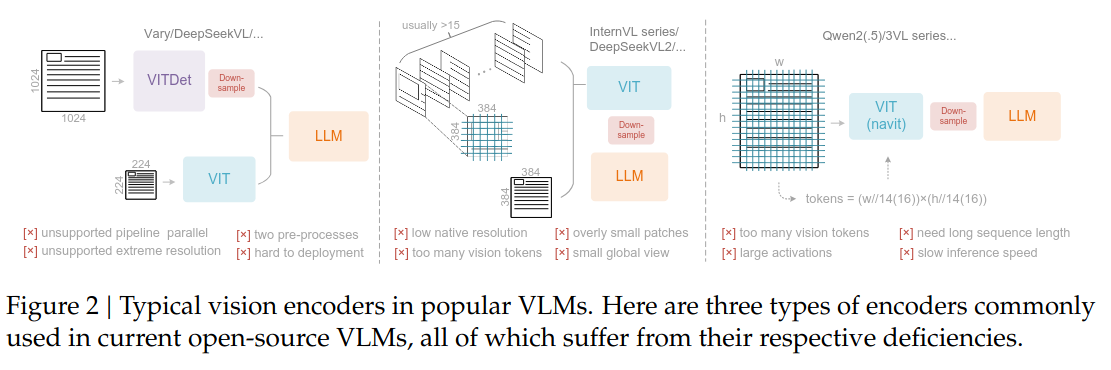
Tiling (InternVL, DeepSeek-VL2)
This is a "divide and conquer" or tile-based method. The high-resolution input is dynamically resized and split into a grid of fixed-size tiles (e.g., ). A global "thumbnail" of the entire image, resized to a single tile, is also generated to retain global context. All tiles are processed by a shared ViT encoder, and the resulting tokens are compressed and projected into the LLM's embedding space. Fusion isn't handled by the encoder; it's implicitly managed by the LLM's self-attention. The main critique is that this can lead to "excessive fragmentation" and a very long token sequence for the LLM.
Adaptive Resolution (Qwen2-VL)
This method adopts the NaViT paradigm, processing the full image directly via patch-based segmentation. The ViT's patchification (e.g., patches) is applied directly, producing a variable number of visual tokens that scales with the image's resolution. This requires modifying the ViT; standard absolute position embeddings are replaced with 2D Rotary Position Embedding (2D-RoPE). Consequently, fusion is handled within the ViT itself, as its global self-attention processes all patches simultaneously. The primary critique is that processing a single, massive image with global attention results in "massive activation memory consumption" due to the quadratic complexity.
DeepSeek-OCR
is a VLM model trained primarily on OCR data. The arch combines a 380M vision encoder with a 3B A570M MoE decoder.
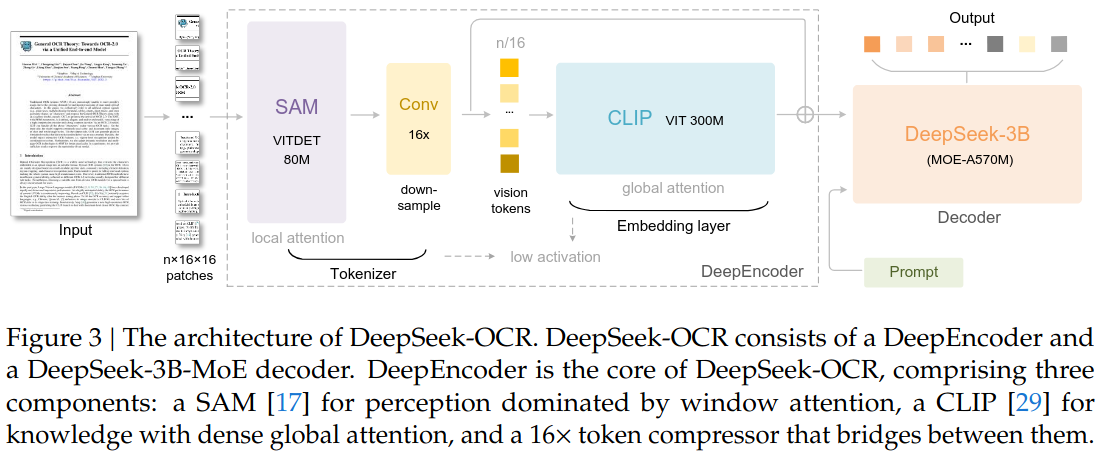
DeepEncoder
DeepEncoder is architected to get the best of both worlds: maintain low activation memory (like tiling) while producing a small, fixed number of highly informed vision tokens (like adaptive resolution). It achieves this by explicitly separating the tasks of local perception and global knowledge fusion in a three-stage pipeline.
Local Perception (SAM-base / ViTDet): The high-resolution image (e.g., ) is first processed by an 80M SAM-base backbone. Using a 16x16 patch size, this stage generates a very long sequence of patch tokens (e.g., 4096). The computational cost is kept low because this component uses primarily window attention.
Local Downsampling (Conv 16x): The resulting 4096 tokens are passed through a 2-layer convolutional module. This compressor performs a 16x downsampling, reducing the token count from 4096 to 256, acting as a local fuser that merges features from adjacent token positions.
Global Fusion (CLIP-large): The 256 locally-fused tokens are then fed into a 300M CLIP-large ViT, which acts as the "global attention" knowledge component. This stack of Transformer blocks performs dense, global self-attention over the 256 tokens, finally enabling the long-range information fusion.
DeepSeekMoE 3B A570M
The decoder side is a DeepSeek-3B-MoE. It fits into the VLM pipeline just as any other would, taking the compressed latent vision tokens from the DeepEncoder and mapping them to match the language model's hidden dimension.
But the MoE architecture itself is quite odd, at least by modern standards. It's got a very high activation ratio of 12.1% with two shared experts. It's also using standard MHA, not MLA or even GQA. The experts are also very wide for this size; with an intermediate size of 896 compared to the model's hidden dimension of 1280, our granularity is as low as 2.85. Recent models usually have around 6-8 in granularity.
concluding thoughts
The real interesting prospect here is the headline idea: using visual compression for text as a better compression method than normal text tokenizers. The paper indicates that 7-10x compression is possible. How does this translate to actual compression? We don't know yet. Could the KV cache be compressed using visual-text compression, perhaps? It's an interesting thought.
It's strange, by some regards the paper feels like an older intern project, but at the same time the results have been extremely impressive and I've heard strong praise from multiple sources. So not sure what to make of this right now. It definitely doesn't have the cadence of a typical DeepSeek release. We've grown accustomed to DeepSeek releases being close to groundbreaking, and that's the expectation they've built. But if we go back to mid-2024, I think we would have just seen this as a normal paper.
Certain aspects make it seem like this work was done some time ago. The components are dated: SAM-1 and CLIP for the vision encoder. The whole idea of using a cheap local attention SAM, then compressing that using conv nets before the more expensive global attention CLIP, seems quite reminiscent of MLA.