More Ling
October 16, 2025
I covered the initial Ling 2.0 releases a few weeks back, but the team has since released several more models. Given the proliferation of similar names, it's worth mapping out the full Ling 2.0 family. The family is best understood as a large-scale empirical validation of the MoE scaling laws proposed in Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models. While that paper established its laws in the - FLOPs regime, the Ling 2.0 series extends this validation up to FLOPs, demonstrating their applicability at extreme scale.
The core model series scales aggressively across three main data points: Ling-mini-2.0 (16B total, 1.4B active), Ling-flash-2.0 (100B total, 6.1B active), and culminating in Ling-1T (1T total, 50B active).
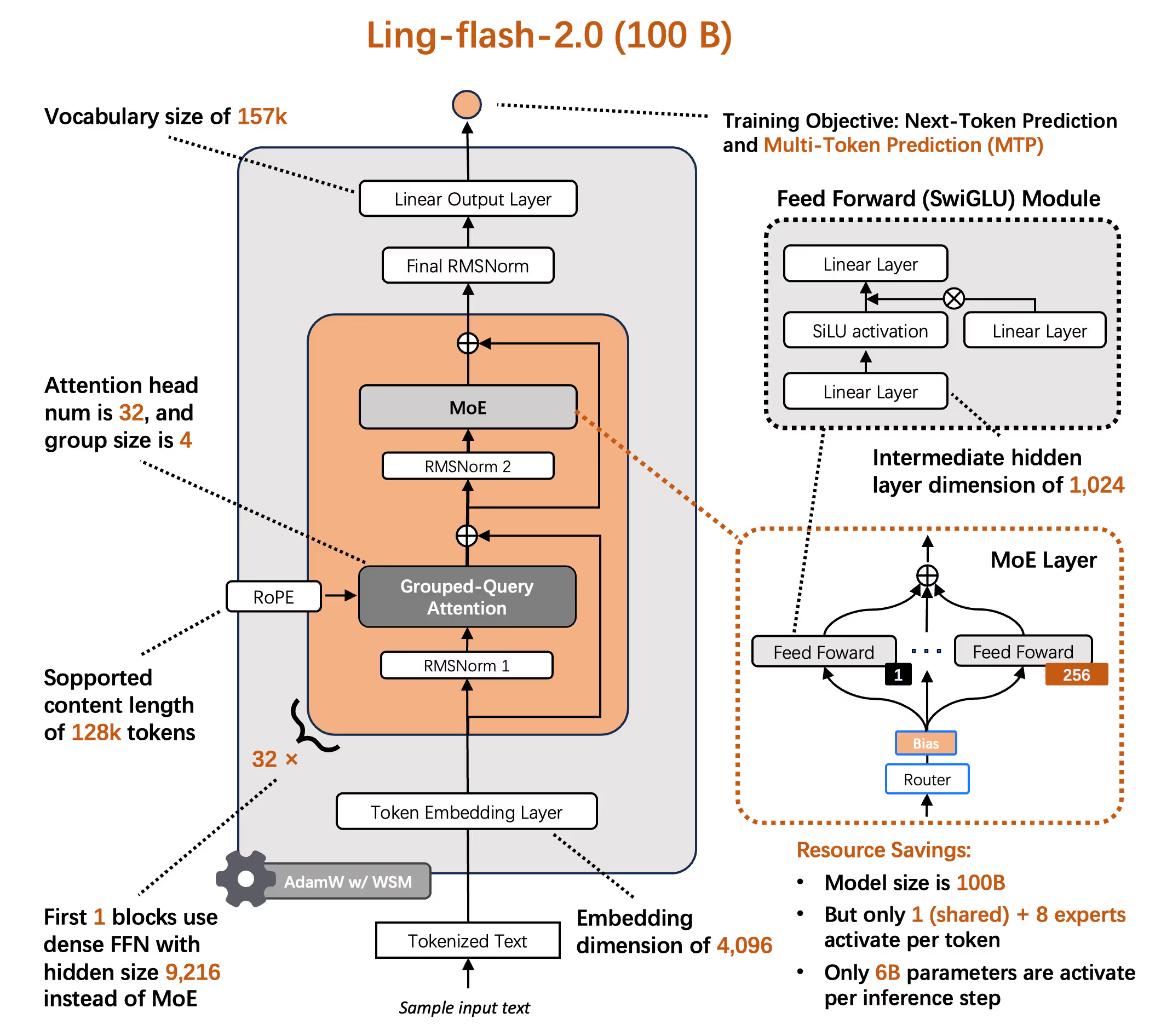
Architecturally, these are standard MoE models; their novelty lies in the hyperparameters (activation ratio, granularity, expert ratios) explicitly chosen to align with the paper's scaling principles. We discussed this in detail previously.
Successfully training the 1T model required significant engineering, most notably stabilizing FP8 at this scale, which is non-trivial. The team partly credit their WSM (Warmup–Stable–Merge) LR scheduler for this, but in reality there are a bunch of undisclosed solutions under the hood that make this possible. Concurrently, they are evolving their alignment stack. The Ling-flash-2.0 release introduced IcePop, a masked importance sampling method to resolve the off-policy training/inference mismatch in RL. The 1T release adds LPO (Linguistics-Unit Policy Optimization), a novel sentence-level policy optimizer that may be analogous to Qwen's GSPO.
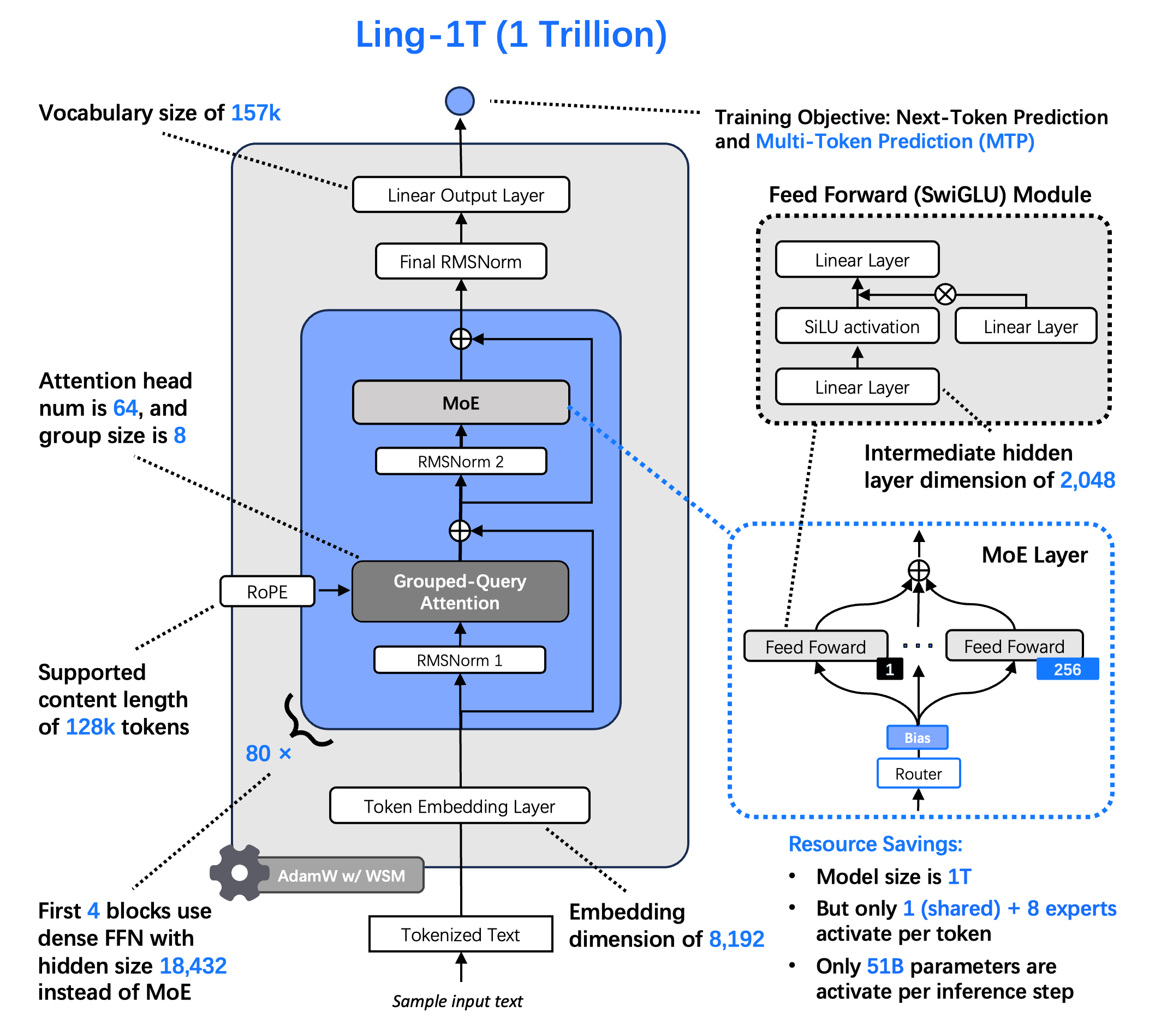
Orthogonal to the base model scaling, the "Ring" variants represent a dedicated reasoning track. Each base model (Mini, Flash, 1T) has a corresponding Ring counterpart, tuned via a joint RLVR and RLHF process. This creates a parallel family (Ring-mini-2.0, Ring-flash-2.0, Ring-1T) optimized for complex reasoning.
The final release, Ring-flash-linear-2.0, deviates from this pattern. It's a one-off architectural experiment: a continuation training of Ling-flash-2.0-base with a new hybrid attention mechanism. This model alternates between standard GQA and a "Linear Attention Kernel" and notably was only released as a "Ring" model.
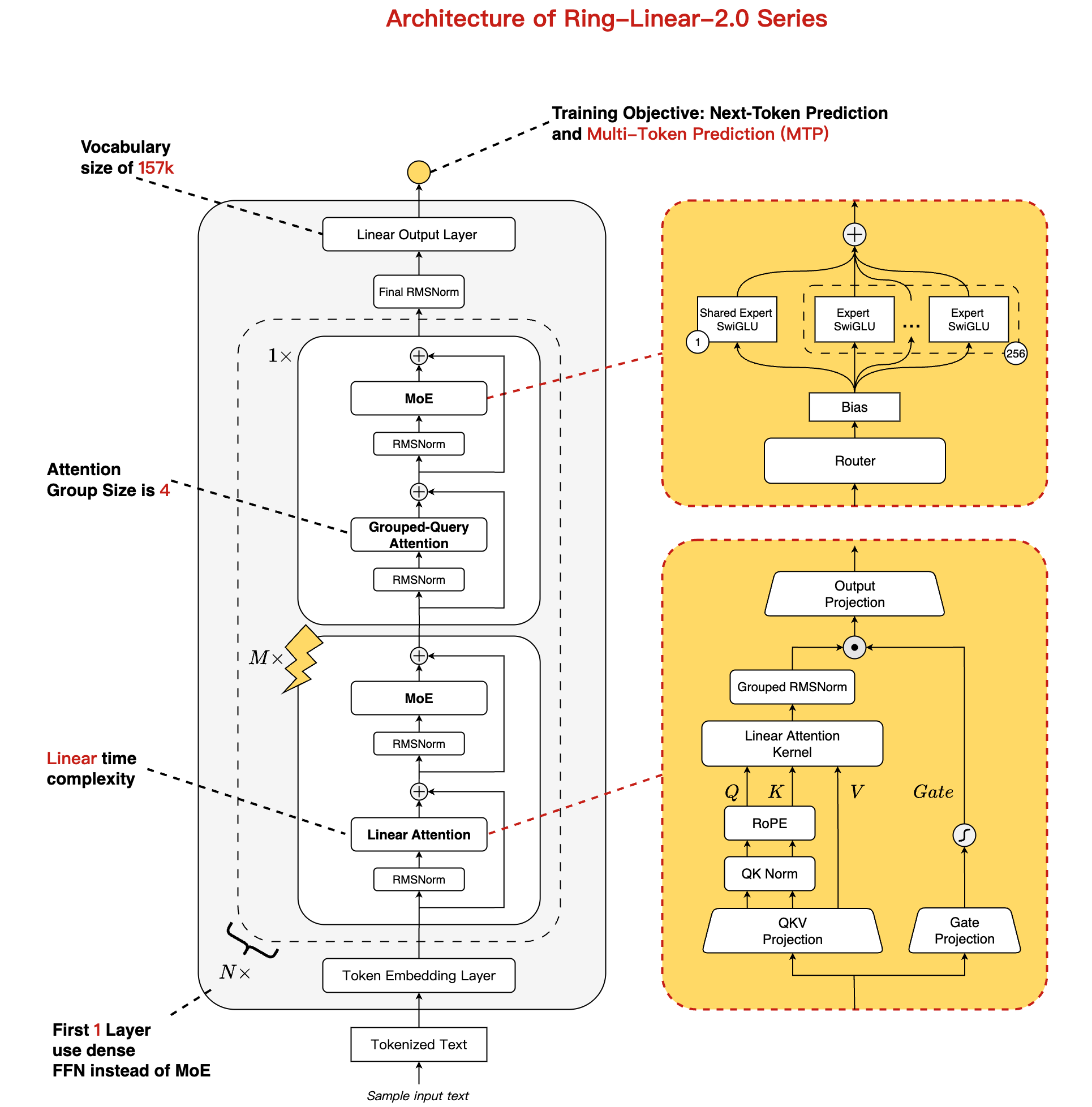
This variant, which also introduces gated attention, was trained for an additional 1T tokens and apparently achieves performance competitive with the original Ring-flash-2.0. Given the timing and architectural similarity (hybrid, gated), this approach strongly suggests inspiration from the Gated DeltaNet used in the Qwen3-Next architecture.
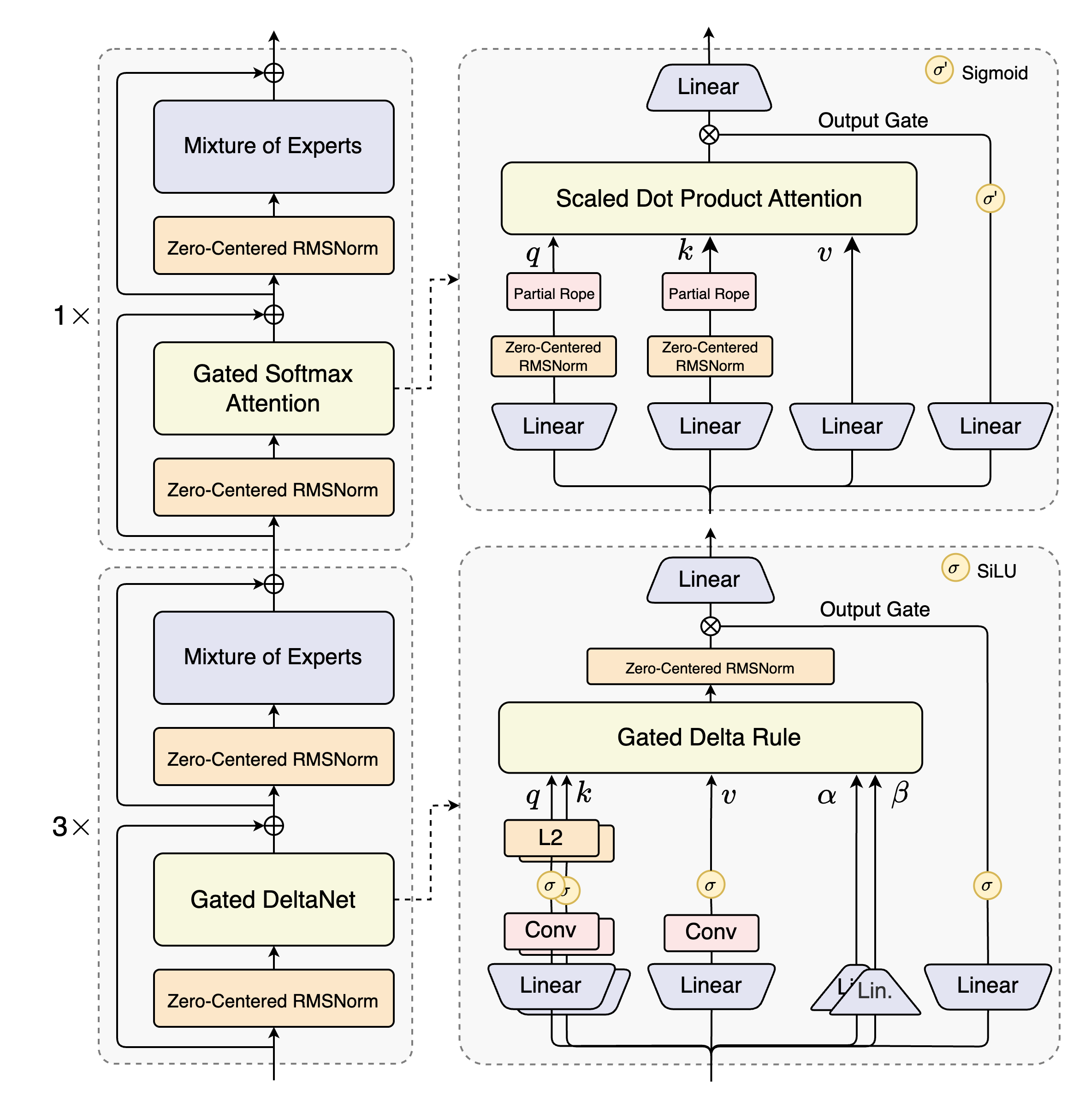
To summarize, this is the Ling 2.0 model family (so far).
| Model | Total | Active |
|---|---|---|
| Ling-mini-2.0 | 16B | 1.4B |
| Ling-flash-2.0 | 100B | 6.1B |
| Ling-1T | 1T | 50B |
| Ring-mini-2.0 | 16B | 1.4B |
| Ring-flash-2.0 | 100B | 6.1B |
| Ring-1T | 1T | 50B |
| Ring-flash-linear-2.0 | 100B | 6.1B |