deepseek sparse attention
Original paper · DeepSeek-AI et al 2025
DeepSeek Sparse Attention (DSA) augments a standard transformer with a lightweight, parallel "lightning indexer." This indexer rapidly scores the entire token history and selects a small, top- set of the most relevant past tokens for each new query. The main, "core" attention mechanism—in DeepSeek's case, MLA—then operates only on this sparsely selected set. This approach dramatically cuts down on the compute required for long-context processing.
In DeepSeek's V3.2-Exp model, DSA is instantiated under MLA in a MQA configuration. This means each compressed, latent key-value entry is shared across all query heads. That being said, DSA's lightning indexer is compatible with any core attention variant.
Why DSA?
MLA (which we'll recap shortly) was by all means a pivotal optimization. It introduced a compressed KV cache, decoupling training and inference attention: models could leverage full MHA during training but run efficient MQA at inference. This design yields massive KV-cache savings while preserving high model quality. The problem, however, wasn't fully solved. The computation under MLA remains effectively equivalent to standard attention; the score calculation is still quadratic, in sequence length.
As context lengths grow—especially in complex, agentic settings—that FLOPs cost quickly becomes the dominant bottleneck. 2025 has seen a wave of linear and sparse attention variants (we previously explored NSA at DeepSeek, but stable training has seemingly proved elusive for DS). DSA represents a more pragmatic and stable intermediate. It bridges the gap by using an extremely cheap indexer (few heads, small head dimension, FP8 precision) to select just surviving tokens. The expensive main attention mechanism then operates only on these survivors, bringing the core attention complexity down to , where .
We'll anchor the rest of this post on the "DSA under MLA" architecture. The diagram below illustrates the two key paths: the new Lightning Indexer (the green path), which scans the history to produce index scores and a Top- selector, and the original Core Attention (the gray path), which now consumes only the selected latent KV entries. You can view this as a fast, compact search stage (the indexer) that gates a powerful but expensive attention stage (MLA); the indexer learns a compact metric space for similarity search, analogous to a learned k-NN.
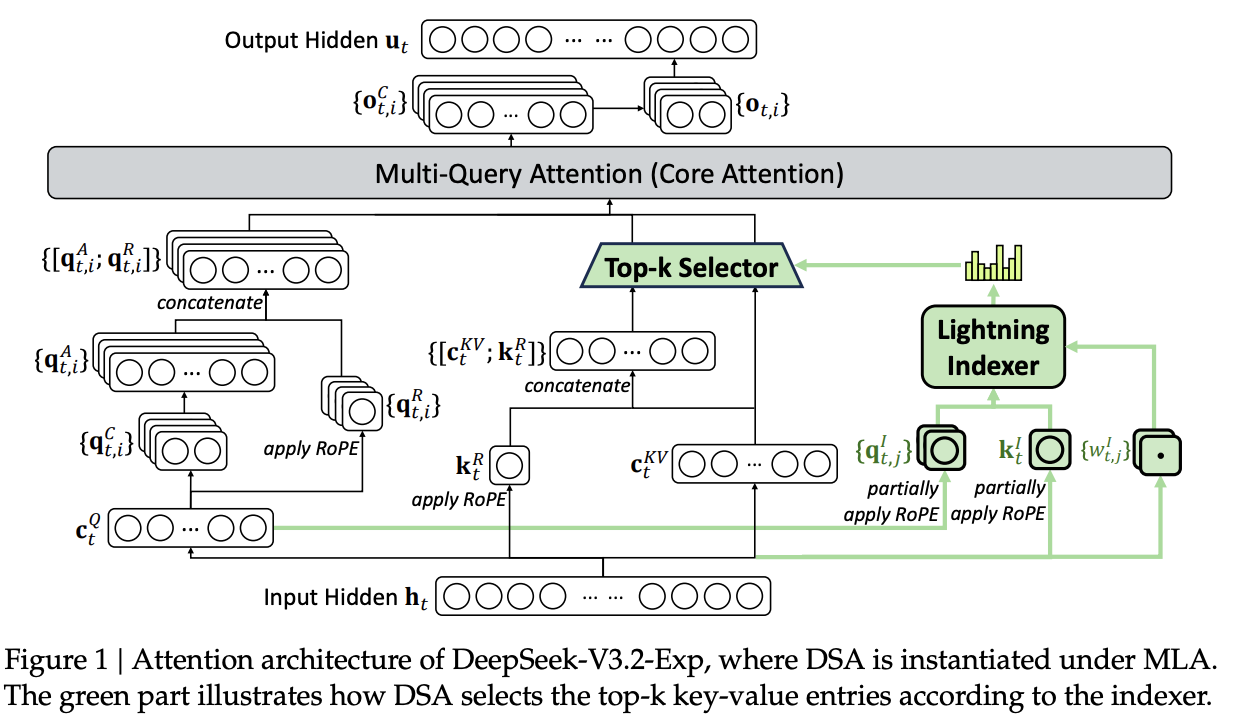
To make sense of the integration, we first need to understand the baseline. We'll recap just enough of MLA to make the DSA modifications obvious, then walk through the indexer's design, connecting the math to the modeling code.
MLA
Let's first establish the MLA baseline. We enter the attention block with hidden states . MLA's core idea is to factorize queries and keys into two complementary channels: a latent channel (which carries the content, or "what") and a RoPE channel (which carries the position, or "where"). Values live entirely within the latent channel.
The KV Path
First, we produce the key-value pre-activations via the "A" projection, . This tensor is immediately split into two parts: the latent KV () and the RoPE key ().
Here, is the dimension of the compressed latent KV, and is the head dimension of the decoupled RoPE key. The latent path is normalized, while the RoPE path gets its positional information.
# x: (B, S, d_model)
kvA = wkv_a(x) # (B, S, d_C + d_RoPE)
cKV, kR = torch.split(kvA, [d_C, d_RoPE], dim=-1) # (B,S,d_C), (B,S,d_RoPE)
# Apply norm and RoPE
cKV = kv_norm(cKV)
kR = apply_rotary_emb(kR, freqs_cis) # (B,S,d_RoPE)
These two tensors are our entire key-value cache. For each token, we store just the compact content latent and the decoupled positional key .
kv_cache[:, start_pos:end_pos, :] = cKV # (B, S, d_C)
pe_cache[:, start_pos:end_pos, :] = kR # (B, S, d_RoPE)
The Query Path
On the query side, we do something similar. We first apply a low-rank "A" projection () and normalize to get a compressed latent query, . (This will be reused later by the lightning indexer, a key efficiency).
# x: (B, S, d_model)
cQ = q_norm(wq_a(x)) # (B, S, d_Q)
Here, is the compressed query rank. To form the final per-head queries, we apply a second "B" projection () from this latent , which expands it into heads. We then split each head into its no-RoPE () and RoPE () subspaces.
# project to heads, then split
q_full = wq_b(cQ).view(B, S, H, d_NoPE + d_RoPE)
qA, qR = torch.split(q_full, [d_NoPE, d_RoPE], dim=-1) # (B,S,H,d_NoPE), (B,S,H,d_RoPE)
# Apply RoPE only to the qR slice
qR = apply_rotary_emb(qR, freqs_cis)
Here, and sum to the full query-key head dimension .
MLA "Trick"
Now we have our queries and our cached keys . A critical component of MLA is that we never materialize the full per-head keys for the entire history. Instead, we use an algebraic trick to score directly against the compact caches.
Consider the no-RoPE score contribution. If we did materialize the key for head at time , we would take the latent and apply the key-block of the "B" up-projection, let's call it .
The score would be the dot product with the query :
This identity is the trick! Instead of projecting all past keys up (), we project the single query down () and compute the dot product in the compact latent space . We transform the query once so it can score directly against the cache.
In code, this query transformation (named q_lat) looks a bit odd, but it's just a reshape and an einsum:
# wkv_b_weight is (H * (d_NoPE + d_V), d_C)
# We view it as (H, d_NoPE + d_V, d_C)
wkv_b = wkv_b_weight.view(H, d_NoPE + d_V, d_C)
# qA: (B, 1, H, d_NoPE)
# Take the first d_NoPE rows (the key block) for each head
q_lat = torch.einsum("bshd,hdc->bshc", qA, wkv_b[:, :d_NoPE]) # (B, 1, H, d_C)
The final scores are the sum of two dot products, both operating on the raw caches:
- Latent Score: The transformed query
q_latdotted with the cache. - RoPE Score: The RoPE query dotted with the cache.
# q_lat: (B, 1, H, d_C), kv_cache: (B, t, d_C)
# qR: (B, 1, H, d_RoPE), pe_cache: (B, t, d_RoPE)
scores = (
torch.einsum("bshc,btc->bsht", q_lat, kv_cache[:, :t_end]) + # latent: \tilde{q}^T c^{KV}_t
torch.einsum("bshr,btr->bsht", qR, pe_cache[:, :t_end]) # RoPE: q^R · k^R_t
) * softmax_scale
Following the softmax, we aggregate the values in latent space using the same cache. This keeps the heaviest computation (the weighted sum) in the compact dimension:
attn = scores.softmax(dim=-1) # (B, 1, H, t)
x_lat = torch.einsum("bsht,btc->bshc", attn, kv_cache[:, :t_end]) # (B, 1, H, d_C)
Finally, we expand this latent representation to the full value head dimension using the value block of the projection (the last rows) and project back to model space.
# Use the value rows (last d_V) per head to up-project
x_head = torch.einsum("bshc,hdc->bshd", x_lat, wkv_b[:, -d_V:]) # (B, 1, H, d_V)
x_out = wo(x_head.flatten(2)) # (B, 1, d_model)
This latent trick is identical to standard attention but avoids ever constructing full per-head keys, saving memory and compute during the decode loop.
DeepSeek Sparse Attention (DSA)
MLA gave us compact per-token caches ( and ) and a decode path that avoids materializing full keys. What it didn't change is how many past tokens we touch: all of them, making the scoring .
The Lightning Indexer adds a fast, low-dimensional search stage before this scoring. It scans the entire history in a tiny, FP8-quantized space and proposes a top- candidate set. The expensive MLA scoring logic we just reviewed is then only run on those tokens.
Building the Indexer Space
The indexer builds its own compact space with (e.g., 64) small heads of width (e.g., 128). This space is separate from the main attention.
Indexer Query: The indexer query path starts from the same compressed query activation that MLA used. This is a key efficiency. We project it to the indexer's head space, split into NoPE and RoPE slices, and apply RoPE.
q_idx = wq_b_index(cQ).view(B, S, H_I, dI_NoPE + dI_RoPE) # (B,S,H_I,·)
qI_nope, qI_rope = torch.split(q_idx, [dI_NoPE, dI_RoPE], dim=-1)
qI_rope = apply_rotary_emb(qI_rope, freqs_cis)
q_mix = torch.cat([qI_nope, qI_rope], dim=-1) # (B,S,H_I,d_I)
Indexer Key: The same process is repeated for the keys, starting from the model hidden state . However, the indexer key path is MQA-style (it's not split into heads), producing a single key vector per token.
Hadamard Rotation: To decorrelate features and improve the numerical properties for low-precision math, both the queries and keys are rotated using a Walsh-Hadamard transform. Think of this as conditioning the vectors for a robust FP8 search.
Scoring and Selection
The indexer runs entirely in FP8. Both the query and key activations are quantized, and the keys are cached in FP8 along with their per-block quantization scales.
q_fp8, q_scale = act_quant(q_rot) # (B,S,H_I,d_I), (B,S,H_I,1 or blocks)
k_fp8, k_scale = act_quant(k_rot) # (B,S,d_I), (B,S,blocks)
# Update the FP8 indexer cache
k_cache[:, start:end] = k_fp8
k_scale_cache[:, start:end] = k_scale
At decode time (), a specialized fused kernel performs the search. This kernel runs an FP8 GEMM between the query and the entire key cache . This is still an operation, but the constants are tiny ( and are small, and the math is FP8).
The kernel computes a nonnegative similarity (using a ReLU) for each head, then performs a weighted sum across the heads to produce a single scalar "index score" for each past token:
Where is the FP8 query for indexer head , is the FP8 key for token , is a ReLU that discards negative correlations, is a learned scalar gate (derived from the current ) that weights the importance of each indexer head and is the per-block dequantization scale for key , which restores the magnitude after the FP8 dot product.
# These weights are derived from x to combine heads cheaply inside the kernel
q_weights = head_weight_proj(x).view(B, S, H_I) * inv_sqrt(H_I)
# The fused fp8_index kernel does all the steps above:
# (B,S,H_I,d_I) @ (B,t,d_I) -> (B,S,t)
# It applies the ReLU, head weighting (q_weights), and k_scales internally.
index_score = fp8_index(
q_fp8, # (B,S,H_I,d_I)
q_weights, # (B,S,H_I)
k_cache[:, :t_end], # (B,t,d_I) FP8
k_scale_cache[:, :t_end], # (B,t,blocks) per-block scales
) # → (B,S,t)
Finally, we top- these scores to find the indices of the (e.g., 2048) most relevant tokens.
The complete DSA loop is as follows:
- Build compact FP8 search vectors (Q and K) for the indexer.
- Run a fast, fused FP8 search to score all past tokens.
- Select the top- token indices.
- Pass only these indices to the main MLA attention layer, which performs its expensive scoring and aggregation.
By filtering the history, DSA lets MLA operate on a tiny fraction of the full context, achieving massive computational savings while maintaining high performance.