GLM-4.5
Original paper · Zeng et al 2025
china doesn't stop, yet another lab coming out the woodworks swinging. GLM-4.5 is a MoE model at >100B parameters. We're seeing a lot of models released in this class right now, DeepSeek, Kimi, Qwen, oh yeah and even OAI with GPT-OSS, all have comparative models at this point. I've heard this paper should have some fun details on their RL infra (slime), which I'm excited to read about. I glossed over the repo a few weeks back and it looked great.
Let's first briefly compare the architecture, the table in the paper provides a nice overview. For reference we have K2 and V3. K2 is the V3 architecture but with 50% more experts in the MoE layers. This change was driven by MoE sparsity scaling law experiments conducted by the Kimi team which found that, under a fixed number of activated parameters (i.e constant FLOPs), increasing the total number of experts consistently lowers both the training and validation loss. They found this to be true up to a sparsity level of 48. Sparsity in this context is the ratio E/k, where E is the total number of experts and k the number of experts active per token. To balance the increased inference cost of more experts, they reduce the number of attention heads to 64, arguing that this only results in a modest performance decrease. So, what does GLM-4.5 do?
GLM 4.5 has 355B parameters, with 32B active. Comparing it to its peers its a lot deeper than DSv3, more similar to Qwen3 in that regard. The MoE sparsity is low at 20. Generally the architecture trades width (in hidden dim and MoE intermediate dim) for depth. The model uses standard GQA as the attention pattern with 12 groups. Going slightly against K2, GLM4.5 increases the number of attention heads to 96 because they observe this increases performance on reasoning benchmarks. QK-Norm (a RMSNorm) is incorporated to stabilize the range of attention logits. Interestingly they incorporate an MoE layer as the Multi Token Prediction layer to support speculative decoding during inference.
| Feature | GLM-4.5 | GLM-4.5-Air | DeepSeek-V3 | Kimi K2 | Qwen3 |
|---|---|---|---|---|---|
| Total Parameters | 355B | 106B | 671B | 1043B | 235B |
| Activated Parameters | 32B | 12B | 37B | 32B | 22B |
| Dense Layers | 3 | 1 | 3 | 1 | 1 |
| MoE Layers | 89 | 45 | 58 | 60 | 94 |
| MTP Layers | 1 | 1 | 1 | 0 | 0 |
| Hidden Dim | 5120 | 4096 | 7168 | 7168 | 4096 |
| Dense Intermediate Dim | 12288 | 10944 | 18432 | 18432 | 12288 |
| MoE Intermediate Dim | 1536 | 1408 | 2048 | 2048 | 1536 |
| Attention Head Dim | 128 | 128 | 192 | 192 | 128 |
| # Attention Heads | 96 | 96 | 128 | 64 | 64 |
| # Key-Value Heads | 8 | 8 | 128 | 64 | 4 |
| # Experts (total) | 160 | 128 | 256 | 384 | 128 |
| # Experts Active/Token | 8 | 8 | 8 | 8 | 8 |
| # Shared Experts | 1 | 1 | 1 | 1 | 0 |
| QK-Norm | Yes | No | No | No | N/A |
post-training
don't have anything to say about the pre/mid-training stage, seems fairly normal. only things that stood out were (1) consistent upsamling of high quality data, and (2) 22T of 4k ctx training, 1T of 32k ctx training and 100B of 128k ctx training. oh yeah, and Moun! that is pretty big, that's now a second lab (both from china) that have managed to train with Moun.
Now, onto post-training. The paper lacks a diagram of this stage, but I made put one toghether that I think is correct, based on their own description.
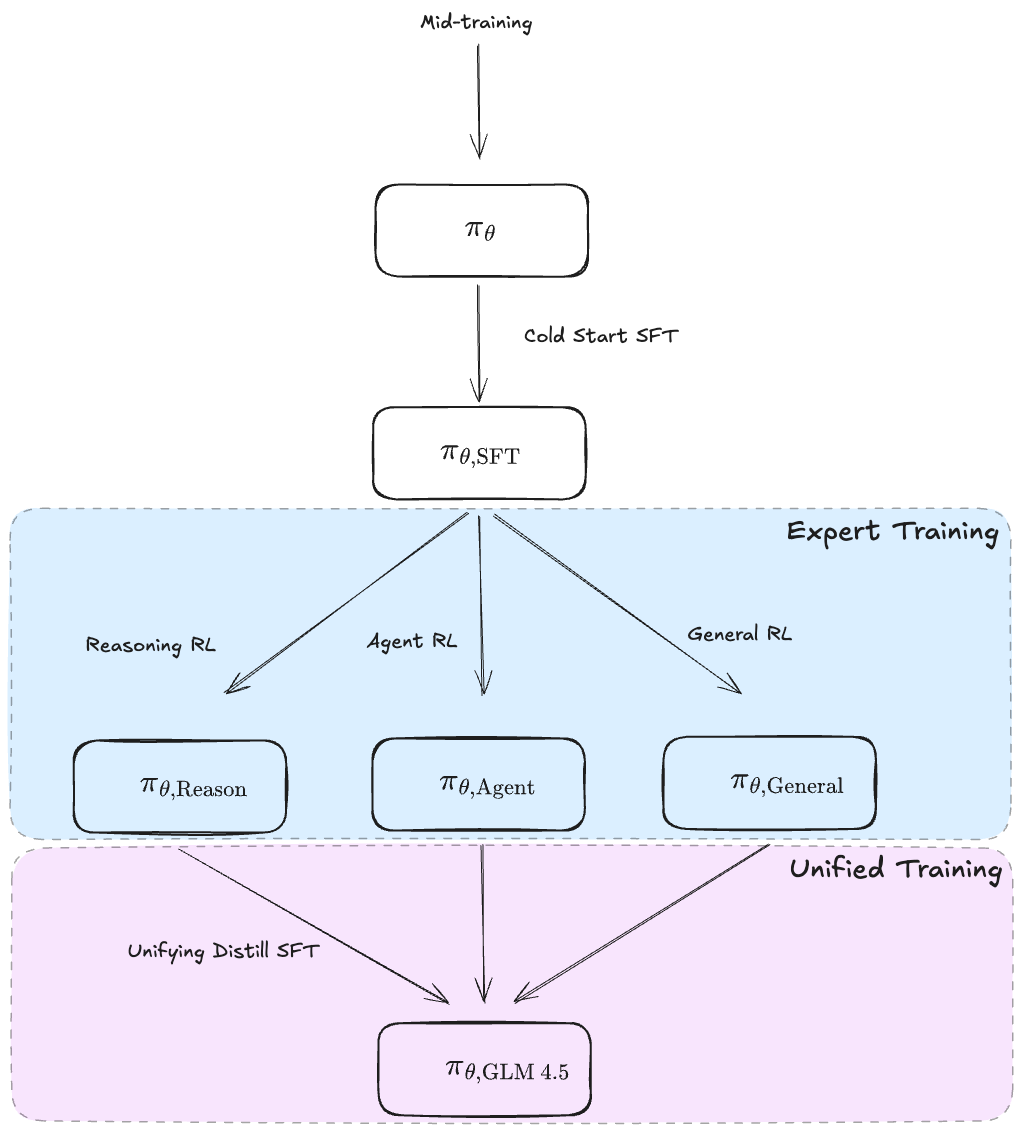
They train three separate expert models from a SFT cold start, specializing in the Reasoning, Agent, and General chat domains respectively. This part is really interesting. These experts are then combined through a self-distilling SFT stage, where the experts generate millions of samples covering their respective domains, and train a base model on these samples with a ctx length of 128k. The output is a hybrid reasoning model. I haven't seen this before, granted I've been bad at reading model papers for the past few months, very interesting. RL is notoriously difficult to get right, and RL on agentic tasks with tool use may look quite different from RL on mathematical problems which makes things even more finnicky. I remember seeing papers talking about this problem, and trying to RL in sequential stages has the problems of destroying the previous stage, so this is a clean way to completely separate the RL. You get three clean individual RL environments where you don't have to worry about the others, you can design the pipelines completely individual, curated for the specific domains then combine them in the unifying SFT stage.
Reasoning RL
focuses on enhancing the model's capabilities in domains that demand logical deduction, structured problem solving and verifiable accuracy. This is the kind of <insert GRPO variant here> RL that we've seen time and time again in 2025. So, what does GLM-4.5 identify as important to their reasoning rl success?
- Difficult-based Curriculum Learning For GRPO to be successful, you want need reward variance, you want problems to be just difficult enough to learn from. If your model is either incapable, or too capable, of solving a problem, there is no learning signal. To address this, GLM-4.5 is trained through a two-stage difficult based curriculum where the training switches to extremely difficult problems at some (unknown) point during training. Once the second stage begins, containing only extremely difficult data (pass@8=0, pass@512>0), the number of generations is increased from 16 to 512. This is a great way to get the most out of your model, unfortunately we don't get a lot of details regarding when to initiate stage 2, how / when the data for stage 2 is curated.
- Output Length There has been conflicting research on whether or not one should gradually increase the maximum output length during RL training. GLMs experiments find that single stage RL at the full 64k length is better than multi-stage rl where the maximum output length is increased in stages. This is probably because GLM start RL from a Cold Start SFT model which has already been conditioned to output 64k length responses, so introducing RL with shorter max lengths causes the model to unlearn its long context capabilities.
- Dynamic sampling temperature It is important to keep a good temperature during output sampling as it directly effects the entropy of our generations which we know to be key in prolonged RL. We need diversity in our generations to be able to discover novel solutions to problems. The paper proposes a mechanism which dynamically adjusts the sampling temperature during training. I'm honestly not a fan of these types of mechanisms, to me they seem like a band-aid solution to a larger systemic issue.
Agentic RL
Agentic training adopts the same verifiable training scheme that Reasoning RL has pioneered. The agentic training focuses on web-search and code-generation agents where every action or answer can be automatically checked. This build in verifiability supplies dense reliable rewards that enable them to scale RL effectively. This model is also trained with group-wise policy optimization, where agent traces are sampled for each problem .
General RL
aims to improve instruction following, human alignment, function calling, remedy potential issues, and improve general performance. This stage is a synergy of rule based feedback, human feedback (RLHF) and model based feedback (RLAIF). Overall I find this expert quite uninteresting, don't have much to say.
RL Infra
The RL framework is called slime, and its been released open source. I haven't had the time to look at it but from what i hear its a very solid repo. It builds on Megatron as the training backend, with SGLang as the inference/rollout framework, its explicitly described as a "SGLang-native" framework, making it slightly unique as most other frameworks tend to prioritize supporting vLLM.
slime supports both colocated, synchronous mode and a disaggregated, asynchronous mode. For General + Reasoning RL, the authors find that a synchronous, colocated mode is more effective, conversely, for agentic tasks where rollouts are protracted and involve complex system interactions, there is benefit to a asynchronous mode. This enables the agent to continuously generate new data without having to wait for the training framework. This flexibility is achieved through using Ray for managing distributed resources. Ray has become the defacto standard framework for managing distributed resources, I see it all the time.
slime implements FP8 rollouts with BF16 training, which greatly accelerates the data generation phase. During each policy update iteration, they perform online, block-wise FP8 quantization on the model parameters before they are dispatched for rollout. FP8 rollouts have been a hot topic in the past few weeks, unfortunately, vLLM does not expose a simple way online dynamic quantization API. I wonder what GLM 4.5 does to mitigate the distribution mismatch between FP8 rollouts and BF16 training.
That seems to be all we get in terms of technical details, the paper continues on with some benchmark evaluations, standard stuff, you can read the paper if your interested in those but that's it for me.