relative entropy
February 22, 2025
the kl divergence term appears frequently in formulations of machine learning, often as a term in the loss function. in relation to language models it typically appears in the objective at the reinforcement learning stage
rlfh
grpo
as a term that "stops the policy from drifting away" from the reference policy . and i feel like most people, myself included, know it to be a measure of the similarity of two distributions, and as such it is typically used to avoid the divergence between two distributions. and that's good; intuitively its easy to grasp, and its easy to understand its use case: we've pretrained an llm on an incredibly rich dataset from which we don't want it to stray too far when applying post-training methods, we more so want to teach it to use this knowledge in a certain way. but learning stuff is fun and we can definitely understand KL divergence better, so how about we give that a try!
KL Divergence, or relative entropy
the first thing to note is that KL divergence is not symmetric, it operates with a base, reference or true distribution. the normal formulation is known as forward KL and reverse KL is, well... the reverse formulation .
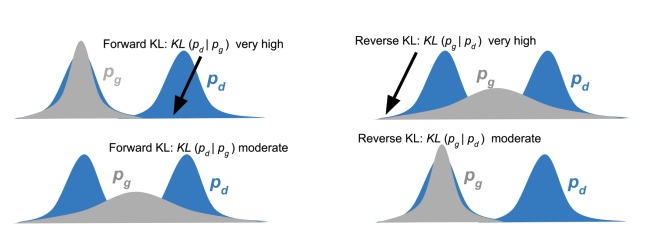
something that may go unnoticed when looking at the KL divergence formula, no thanks to it's completely uninformative name, is that it is actually measuring entropy, or relative entropy between two distributions. remember how entropy
and cross entropy
are formalized. Can you see it?
Both are tools to measure the difference between two distributions, but as opposed to cross entropy, by subtracting the entropy of the true distribution , can be interpreted as the expected number of extra bits per message needed to encode events drawn from true distribution . Another way of putting it is the expected excess surprise form using as a model instead of . It also has some nice properties for comparing distributions. For example, if and are equal, then the KL divergence is 0.
In practice, especially when training language models, calculating the true KL divergence is not feasible, we can't sum over analytically. Instead, numeric libraries will approximate the KL divergence with an unbiased estimator. John Schulman has a nice blog post on this topic.
another thing to note is that we're often working with logprobs instead of probs, because they are much "nicer" in terms of numerical stability. this means we prefer kl divergence on this form
we can see this in the torch source code
Tensor kl_div(const Tensor& input, const Tensor& target, int64_t reduction, bool log_target) {
TORCH_CHECK(!input.is_complex() && !target.is_complex(),
"kl_div: Complex inputs not supported.");
TORCH_CHECK(!at::isIntegralType(input.scalar_type(), /*include_bool*/true) &&
!at::isIntegralType(target.scalar_type(), /*include_bool*/true),
"kl_div: Integral inputs not supported.");
Tensor output;
if (log_target) {
output = at::exp(target) * (target - input);
} else {
output = at::xlogy(target, target) - target * input;
}
return apply_loss_reduction(output, reduction);
}
where log_target identifies whether the targets are already log probs, and the input is already in log form.