multi-head latent attention
January 2, 2025
DeepSeek V3 is an astonashing feat of engineering, model performance aside (the topic seems contentious, i've heard mixed opinions so far, apparently it keeps getting stuck in a reasoning spiral), being able to train a model of this capacity on a 2048 H800 cluster.... in just 4 GPU days? Crazy. They only spent $5M dollars training this thing. Also, from what I hear, the DeepSeek team is barely >100 people, and it's all in-house Chinese talent. I mean if you were worried about China's development before... yeah I don't know, they're fucking good that's all I know.
enough raving about the DeepSeek team, one of my favorite things about DeepSeek's models, are their attention mechanism, so i'd like to provide a formal introduction to: Multi-head Latent Attention; MLA. MLA was first introduced in DeepSeek V2, back in spring earlier this year i believe? I spent some time digging into it back then, but unfortunately my mind is slipping on the details so i'm going to take another pass at it and you can come along with me. i'll be looking at it through a the perspective of the historical evolution of attention mechanisms: MHA -> MQA -> GQA -> MLA. The content below is heavily inspired (a considerable amount os directly translated) by a post from Jianlin Su, the author of RoPE, who runs an incredible blog, in chinese.
MHA
Multi-head attention is the traditional attention mechanism defined in Attention is all you need. Suppose the input sequence consists of row vectors where , then MHA is formally represented as:
An example configuration (Llama 3.1 70B) of the above parameters is . Note that is common practice.
During inference a causal autoregressive language model generates tokens recursively, meaning the generation of token does not affect the previously computed matrices . These matrices can be cached in a KV cache to reduce redundant computation, trading compute for memory. However the KV cache grows with both the model size and input length. At sufficiently long context lengths, the KV cache can consume the majority of GPU memory, often surpassing the memory required for model parameters and activations (albeit flash attention and other low level optimizations have aleviated the issue). This scaling issue makes it a bottleneck for efficient inference, especially for models serving long inputs.
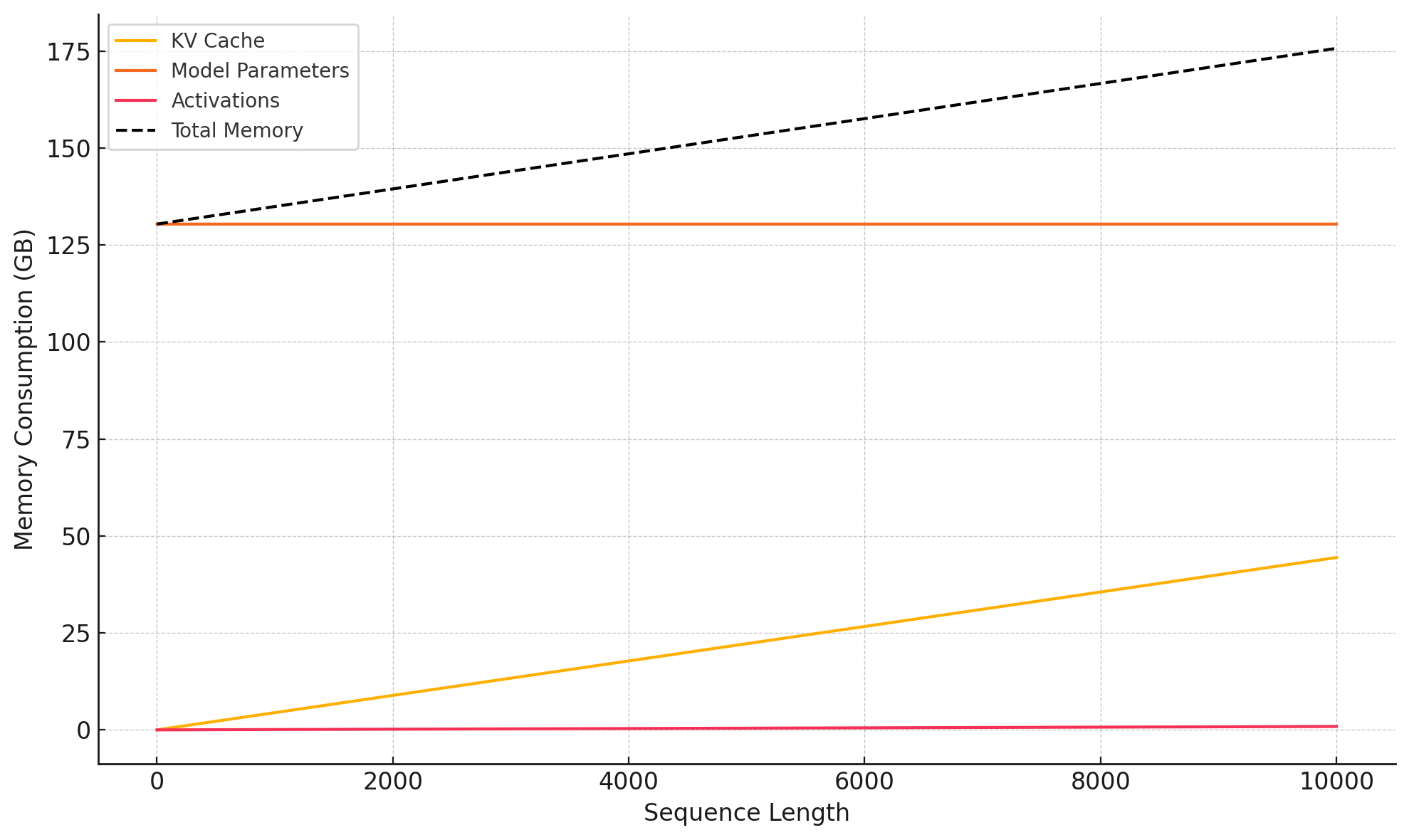
A solution would be to deploy such models across multiple cards, or when necessary across multiple machines. However, a guiding principle when deploying models across a GPU cluster is that intra-card communication bandwidth > inter-card communication bandwidth > inter-machine communication bandwidth. The more devices a deployment spans, the higher the communication overhead + cost becomes. Thus, we aim to minimize the KV cache such that we can serve long context models on as few GPUs as possible, with the ultimate goal of lowering inference costs.
This provides the guiding motivation behind the subsequent developments to the attention mechanism.
MQA
Multi-query attention (MQA) is the extreme alternative to MHA, published in the 2019 paper Fast Transformer Decoding: One Write-Head is All You Need it represents the cautionary reaction to the apparent problems of the KV Cache. If one understands MHA, understanding MQA is simple: let all attention heads share the same key and values. Formally, this means canceling the superscripts of all in MHA:
In practice, the heads are broadcast in-place across heads during computation. This reduces the KV Cache to of the original size, which is a significant reduction. It does however suffer in performance, but MQA supports claim this can be offset by increased training time. The "saved" parameters can be shifted to the FFN to make up for some of the lost performance.
GQA
Grouped Query Attention is the generalized version of MHA and MQA, published in the 2022 paper GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. GQA divides the KV heads into groups (where evenly divides ), where each group is paired with 1 or more query heads. Formally, this is expressed as:
GQA generalizes MHA and MQA by varying the number of attention groups . When it replicates MHA; when it corresponds to MQA; and for , it compresses the KV cache by a factor of . This flexibility makes GQA a more versatile and efficient implementation, as it allows precise control over the trade-off between compression and computational cost.
An important advantage of GQA is its inherent support for parallelism in attention computation. In large models, where a single GPU is insufficient to store the full model, attention computations can be parallelized across heads, which are independently processed before concatenation (see formulas above). By selecting to align with the number of GPUs used for parallelization, GQA minimizes inter-device communication overhead, enhancing scalability and efficiency.
MLA
Now that we've laid the groundwork with MHA, MQA, and GQA, we're ready to tackle Multi-head Latent Attention (MLA). At first glance, MLA introduces a low-rank projection of the KV Cache, to which a reader may question "Why did it take so long until someone proposed a low rank decomposition of the KV Cache considering how long LoRA has been around?"
However, consider what happens in GQA when we stack all together:
If we consider to represent the concatenated , and the corresponding projection matrices as we see that GQA is already performing a low-rank projection. Generally, we have that , so the transformation from to is a low-rank projection. As such, the contribution of MLA is not the low rank projection itself, but rather what happens after the projection.
Part 1
GQA downprojects the into , splits the matrice into two halves for and , then further divides this into parts and replicates each part times to "make up" the and required for the heads. While effective, this approach imposes structural rigidity, enforcing a fixed grouping and replication scheme. MLA recognizes that these operations are simple linear transformations, and therefor replaces them with a learned learned linear transformation. This transformation projects into a shared latent space, capturing features in a compressed form and increasing model capacity.
Once is derived, it serves as the basis for generating head-specific keys and values. For each attention head , a linear transformation is applied to map into the full query space :
Theoretically, this increases model capacity, but the goal of GQA is to reduce KV Cache, so what happens to our cache? In GQA, we would cache our downprojected , however, MLA's approach recreates all KV heads, causing the KV Cache size to revert to that of MHA? Interestingly, the authors leave this be during training, but then circumvent this issue during inference by caching only and fusing the projection matrices with subsequent operations. Notably, is independent of , meaning that it is shared across all heads, MLA transforms into MQA during inference.
Part 2
Everything seems exemplary at first glance; but the observant eye will that our inference scheme is incompatible with RoPE. Earlier, we mentioned that we can cache during inference, not needing to compute , why was that? In the dot product attention, and are combined as
with the last reformulation, we can combine as the projection matrix for Q, replacing with . Now, this was possible because are simple linear transformations with no external dependencies. However, RoPE changes the dot product attention of MLA:
which introduces a term that depends on the position difference . encodes dynamic relative position information, at runtime, breaking the assumption of position independence that MLA relies on to cache only . One might be asking why we can't just cache the compressed representation and recompute on demand, this would still reduce the memory footprint of our KV Cache? Well we'd have to re-calculate at every token position, effectively making the cache redundant. Unfortunately, this problem is fundamental to RoPE, and even though DeepSeek reached out to Jianlin himself they were unable to find a clean solution.
The published approach is a hybrid design. It splits the representation of queries and keys into two distinct components: content dimensions and RoPE dimensions . These two components serve different roles while preserving the benefits of both MLA's KV cache reduction and RoPE's relative position encoding.
For queries:
and for keys:
The content dimensions are derived from the shared latent representation , which is cached across all heads and independent of position. These dimensions can continue as described in part 1 above.
The RoPE dimensions are derived directly from the input and are position-dependent through the application of . These dimensions capture positional information and interact during the attention computation to retain RoPE's property:
This ensures that relative positional relationships are encoded, preserving the benefits of RoPE without needing to embed positional encoding into .
During attention computation, the score for the query at position and key at position becomes:
Here, the content dot product relies only on , allowing the earlier "dot product trick" (fusing and ) to be retained. Meanwhile, the RoPE dot product directly incorporates relative positional information using .
Only a small additional overhead for (e.g., ) is added to the KV cache for shared RoPE dimensions, minimizing memory growth.
concluding thoughts
pff, okay that was a mouthful. MLA is honestly quite difficult to just grok upon first look imo, if it weren't for the RoPE embeddings it would probably be a lot easier honestly, apparently they did try alternative embeddings schemes but nothing worked as well as RoPE. The whole solution would be a lot cleaner as well, but alas... Either way this blog post as a whole by Jianlin is fantastic, I have yet to find a better deep dive on MLA. Heavily enjoyed this, thank you Jianlin.