Training Large Language Models to Reason in a Continuous Latent Space
December 27, 2024
another paper from FAIR that has garnered significant attention this december.
chain-of-thought (cot) reasoning has long been known (relative to the existence of llms) to enhance the reasoning performance of language models. not only does it improve reasoning, but it also allows users to verify the steps taken to reach an answer. in 2024, the trend has been to use cot reasoning traces as a training signal. o1 was the first notable release in a class of models explicitly trained to produce such reasoning traces. generally, the sentiment is that this type of test-time reasoning "search" is the way forward.
a major question has been how to combine reasoning traces and verifiers with self-play, rl, and alphazero-style training—the techniques that propelled game-playing bots to superhuman performance. in parallel, there has been an ongoing discussion about how to "train" models to reason effectively. a critical concern is whether forcing the model to "talk" through its reasoning, essentially verbalizing every step, is the right approach or whether it introduces unnecessary constraints.
now that we've covered a broad set of questions related to model reasoning and why it’s important, what does this paper tackle? essentially, we want our models to reason effectively, and we know they already compute their thoughts and calculations in a latent continuous space. so why, during reasoning, do we force them to output discrete tokens from a restricted vocabulary? why not let models reason in the very space they are already using for computation? surely, the continuous latent space is far more expressive and natural for the model than the discrete token space we currently force it to output into, right? this brings us to COCONUT.
the idea behind coconut is simple: during cot reasoning, instead of feeding a token back into the model, coconut treats the last hidden state as a representation of the reasoning state and directly uses it as the next input embedding. consider a standard embedded input sequence to a transformer model:
where is a token. In COCONUT, the language model switches between this language mode and a new latent mode:
.
Here, the model enters latent mode for , using the hidden state from the previous token to replace the input embedding. special tokens
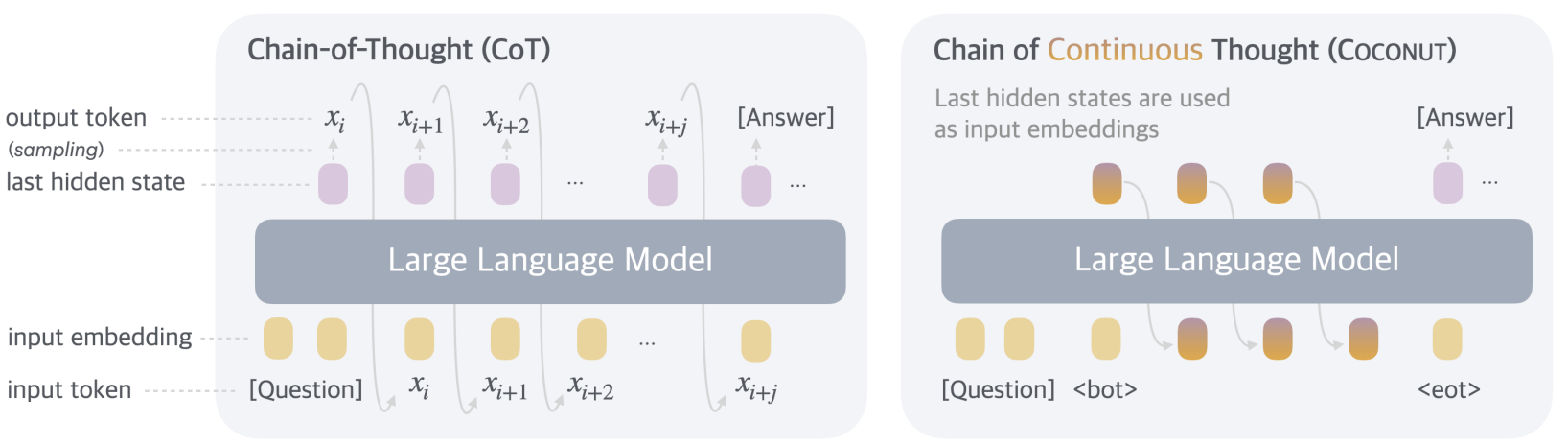
to me, this is a strikingly simple approach. for training, the authors use a language CoT dataset and iteratively replace more steps of the reasoning process with latent thoughts. this approach encourages the continuous thoughts to facilitate future reasoning and helps the model learn more effective representations of reasoning steps than can be expressed in human language. interestingly, the results show that this curriculum-style training is crucial—without it, the model performs no better than a no-cot baseline.
one would hope that reasoning in the latent space enables the model to tackle more complex reasoning steps. the continuous space should allow the model to explore a more diverse reasoning space. by strategically switching between latent mode and language mode, the authors analyze COCONUT's reasoning process. COCONUT's reasoning appears to resemble a latent search tree. while normal cot is forced down a predetermined path, always focused on the immediate next step (making it shortsighted), COCONUT seems to traverse a breadth-first search (bfs) style tree, progressively exploring and pruning paths. latent space reasoning avoids committing to a hard choice too early.
given that continuous thoughts can encode multiple potential next steps, latent reasoning can be interpreted as a search tree rather than just a reasoning chain. even more fascinating is the structure of this latent search tree. unlike a classic bfs tree, which explores all branches uniformly, the model demonstrates an ability to prioritize promising nodes while pruning irrelevant ones. by decoding into language space, the authors analyze the probability distribution of the next step. viewing this distribution as an implicit value function reveals how it guides the latent search tree.
by analyzing this value function, the authors observe that the model assigns higher value to "promising" branches—those more likely to lead to the correct result. this indicates that the latent space is not only more efficient but also a better medium for reasoning.
final / concluding personal thoughts. COCONUT stands out as one of the first clear and compelling examples of the long-anticipated potential of latent space reasoning. allowing reasoning to occur in the continuous latent space aligns well with the computational structure of llms and addresses limitations of token-level reasoning. the results are promising, particularly for tasks requiring complex planning, though the reliance on curriculum training and latent interpretability remain challenges. a constant worry of latent space reasoning lies in the opacity of its processes, potentially making reasoning steps less interpretable for humans; however, coconut's seamless ability to switch between the two modes may prove a promising avenue to mitigate this risk.