Byte Latent Transformer: Patches Scale Better Than Tokens
December 26, 2024
it's been a while. happy to be back reading some papers, i've got some that i want to get through over the christmas break.
BLT, byte latent transformer, is an attempted takedown of the bpe tokenizer monopoly by allowing a transformer to train on raw bytes without a fixed vocabulary. the papers proposes dynamic segmentation of raw bytes into patches based on the entropy of the next-byte prediction, creating contextualized groupings of bytes with uniform information density. while tokenization-based models are "stuck" allocating the same amount of compute to every token, blt builds on the central idea of enabling models to dynamically allocate compute where it is needed. a large transformer may not be needed to compute the ending of most words, since its a low-entropy decision compared to predicting the first word of a new sentence - speculative decoding anyone? - also, tokens are pre-computed based on some corpus which may not match the complexity of predictions in a downstream task.
the usage of entropy in blt is analogous to its role in entropix; it has become a central metric for dynamically allocating compute. by quantifying the certainty of the next prediction, systems can decide how much compute to allocate. in entropix, this is achieved through a context-aware sampling strategy that dedicates more transformer steps to uncertain states, while blt routes inputs to different models based on entropy.
reading the premiss of the paper, and the theoretical motivation to patch vs tokens, i honestly thought the implementation was going to be quite straightforward, but it took me a while to understand how BLT works, in practice.
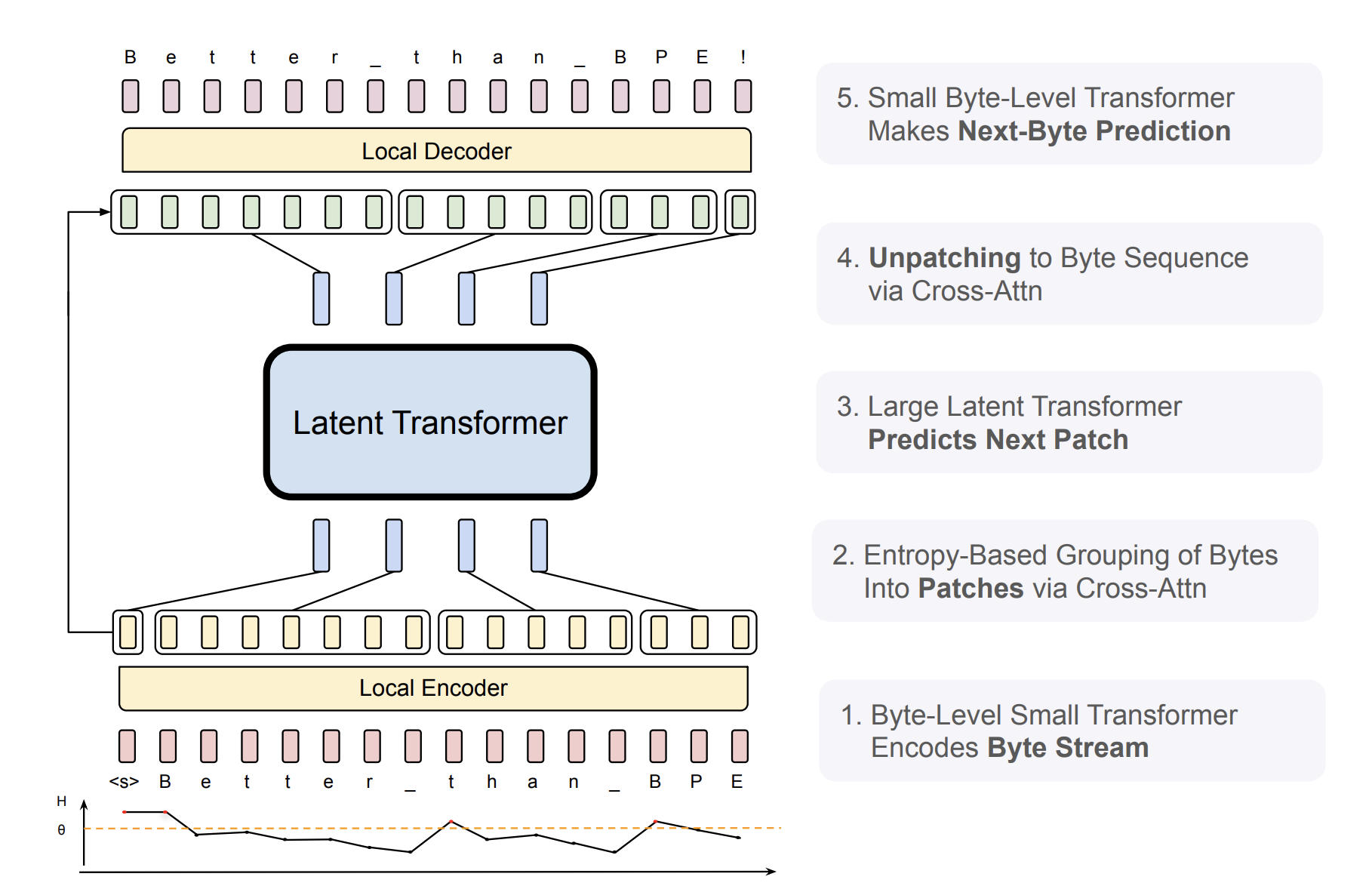
first off, central to the entire architecture, are the two "circuits" at play. there's an outer loop consisting of the local encoder and decoder, which will take N steps to process a sequence, and an inner loop that includes the latent transformer, taking M≤N steps, where M is ideally much smaller than N. this ties back to what i was saying before: the latent transformer (a standard transformer) is only invoked at patch boundaries when the entropy model determines that the next byte is uncertain. when there are many possible paths forward, we allocate compute (via the latent transformer) to make this decision.
to exemplify, consider generation at step "< s >". the entropy model deems this state to have high entropy, meaning we mark it as a patch boundary and generate a patch embedding of "< s >" using the local encoder. from the local encoder, we also receive "hidden states" (embeddings or latent representations) of the byte stream, which, in this case, is just "< s >". the patch embedding is passed to the latent transformer, which generates an output patch representation of "< s >" and predictions for the next patch. the local decoder then uses this patch output representation, along with the byte encoder's hidden states, to generate the next byte, "B."
so far so good. but what happens next? now we've got "< s >B," and the entropy has fallen below the global threshold, meaning we no longer want to invoke the latent transformer. the paper is sparse on details about what happens here. there is code available, so i can't really complain, but i haven't had the time to look at it yet. i do, however, have a hypothesis—or an estimate, if you will. as i understand it, the local encoder re-generates the patch embedding for "< s >", including the hidden state of byte "< s >" (a kv-cache likely applies here), but now it also produces the hidden state of byte "B." if we input these byte hidden states, together with the already computed latent patch representation, into the local decoder, it will generate the next byte without incurring compute from the latent transformer, producing "e".