llama/phi-3, scaling laws, and the benchmarking conundrum
April 23, 2024
For the first time since its release, people seem to be wavering in their confidence in Chatbot Arena. This thread caught my attention. It seems as if the release of Llama 3, and the models initial ranking has led people to question not only Llama 3 but the whole leaderboard itself. After letting the dust settle, I can confidently say that this vexation is unfounded.Llama 3 is a great model, and the Chatbot Arena remains a solid proxy for human judgement. Should they have waited a few days to let the CIs settle before making the elo public? Maybe. Take a look at what happens to the rankings when we filter for only English conversations
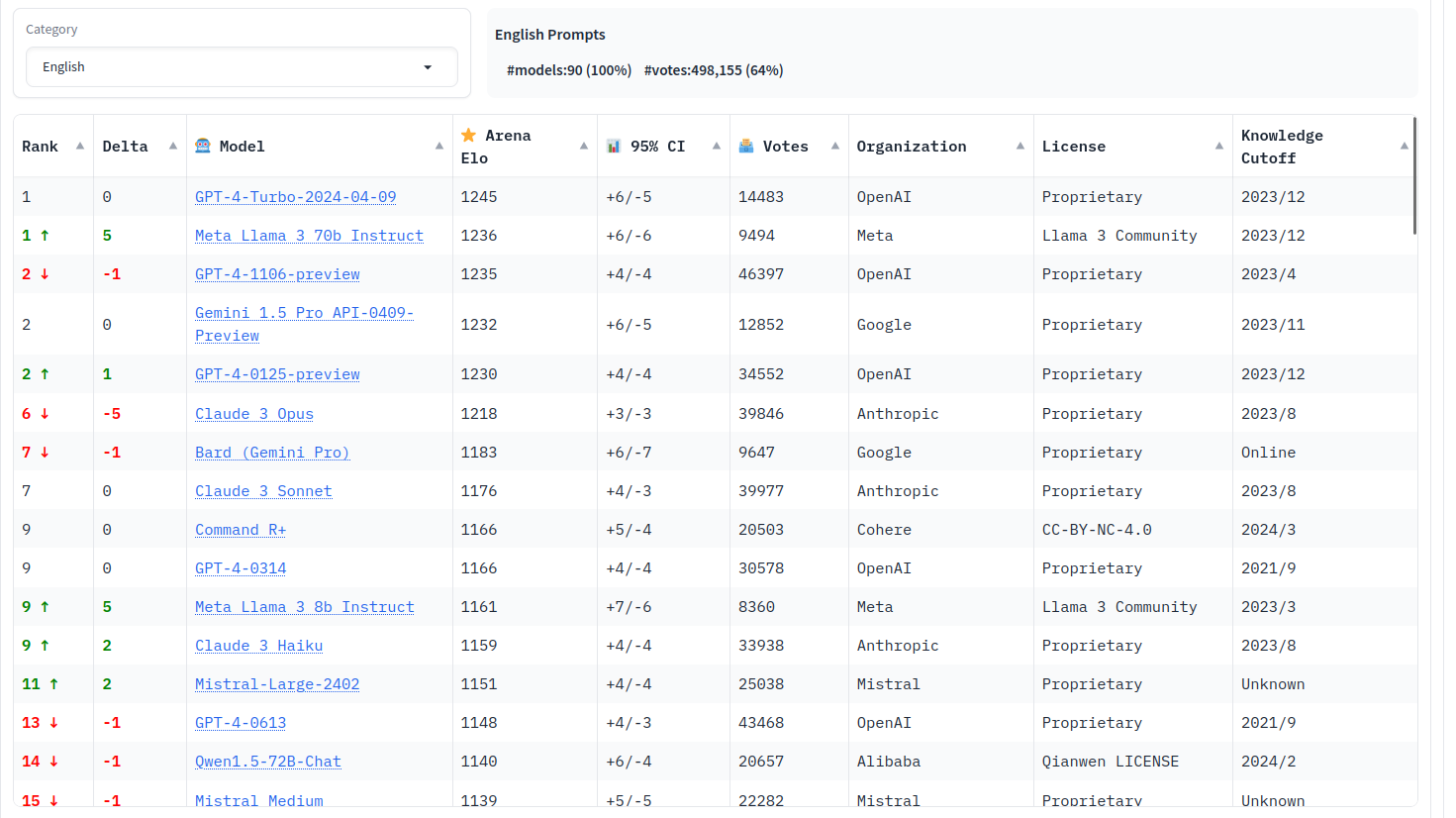
This is a valid differentiation given Meta's own details of the training data

I'm bullish on Llama 3. That being said, the arena is still a populist metric. We still don't have a way to evaluate what intelligence in these models mean, and this is is partly because we lack definition. It's more than likely possible to boost your elo a few points by tuning the style at which it responds.
What I'm stumped on is if Llama 3's edge is in the pre-training or instruction tuning stage. After seeing independent evals of the base models it seems that the 8B base model barely edges out Mistral 7B, ~10% better. Now this would make sense looking at the parameter delta but when we consider the total compute budgets (Params Tokens) it rather begs the question of whether smaller models are saturated. As I see it there's two takes on this: a) the total compute poured into LLama3 8B is what enables the instruct model to perform at the level it does. b) the base model is on par with Mistral 7B and Meta's accosted instruction tuning dataset is what boosted performance. I guess we'll see what other creators can do with the base model, looking forward to Llama-3-Hermes.
Scaling laws? (again)
This discourse, with the release of both Llama-3 and Phi-3 has extended into a familiar debate around the scaling laws. Some starting to question whether the original paper may have even hampered LM progress? This is overdramatic. I refuse to believe the paper did anything but convince the field to shift their focus towards the data, rather than parameters. That being said there has been a noticeable trend of training models beyond the limits prescribed by the once-acclaimed chinchilla compute-optimal laws. This is partly because you trade training compute for later inference efficiency (e.g. train smaller models for longer) but also because we're not seeing the type of diminishing returns one would expect. From Meta's release blog post: while the Chinchilla-optimal amount of training compute for an 8B parameter model corresponds to ~200B tokens, we found that model performance continues to improve even after the model is trained on two orders of magnitude more data. Both our 8B and 70B parameter models continued to improve log-linearly after we trained them on up to 15T tokens. It's clear that the exact formulas proposed in the scaling papers don't apply (the irreducible term that was estimated for MassiveText is higher than the resulting loss we see on todays models). But what the exact reasoning for this is is still unclear. Higher quality data filtering? The rise of Synthetic data? Since Chinchilla we've taken a lot of strides in data curation, very little of which the open-source community been privy to... you'll note that data remains the most elusive part of "open-source" models.
Phi-3
The release of the Phi-3 model adds another layer to this complex narrative. The model seems to either be a 'benchmarkmaxxing' outlier or a genuine innovation outlier, depending on one's perspective. The MMLU in particular looks crazy given the compute budget, but I guess we'll have to wait for the vibe checks. Phi-3 does not innovate in architecture but emphasizes an optimal data regime, focusing on high-quality, synthetic, and heavily filtered data over mere quantity. This approach challenges the traditional focus on architecture and compute, highlighting their view on the importance of data quality.
Benchmarks
However, these innovations bring us to a recurring and crucial query: How effective are our benchmarks, really? Recent discussions, especially those sparked by the analysis of the Phi-3 paper, have brought this question into sharper focus. Have you ever stopped to look at the benchmarks by which we guide our intuition of base models for example? MMLU is the primary source of judging LLM base models, it's what most creators, authors and spokespeople refer to when discussing SOTA models. That being said, take a look at some examples from MMLU's test set. I don't need to say much more. There's also repeated cases of questions that are out of context or just straight up broken (samples taken directly from the dataset):
The complexity of the theory.?"1,2,3,4","1,3,4","1,2,3","1,2,4",C Demand reduction,?"1,3,4","2,3,4","1,2,3","1,2,4",D Predatory pricing.,?"1,2,4","1,2,3,4","1,2","1,4",D The need to head off negative publicity.,?"1,3,4","2,3,4","1,2,3","1,2,3,4",C They are too irrational and uncodified.,?"3,4","1,3","2,3","4,1",B The purposes for which the information is used is in the public's interest.,?"1,2","1,3","2,3","1,2,3",A How the code is enforced.,?"1,2,3","1,2,4","1,3,4","2,3,4",B
We've been talking about this problem for a long time now and we're still stuck here with the same ways to judge our models. I am however conflicted on this topic - I read a thread from Greg Kamradt (creator of the Needle-in-a-Haystack test) that dismissed MMLU's value as a benchmark completely but I don't agree with this take; We want our models to reason and generalize, but at the same time, I want my models to know stuff! That entails benchmarking both of these capabilities, either combined or separately, but that's for the future to decide.
Just to note, TruthfulQA suffers from the exact same issues.
When it comes to evaluating instruction-tuned models we've got a lot more sophisticated tools to do so imo. MT-Bench, Alpaca Eval 2, EQ-Bench are all great examples of this, I think everyone should check out AlpacaEval 2 since they released their length adjusted version. LMSys is continually working on improving Chatbot Arena and recently announced a new HARD benchmark that's in the pipeline. I'm hopeful about this stuff, and quite confident we're able to gauge good IFT models from bad ones, but on the base model side we're still grasping at straws