OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement
Original paper · Zheng et al 2024
I often get asked what model one should use for code generation, and unfortunately the answer to this has always been GPT-4. There simply haven't been any solid alternatives that are worth the effort. Now, although I haven't tried the model presented by our authors here today, I'm quite confident that this is going to remain the case. So, why are even here? talking about this paper? well, because this is probably the closest display of gpt-4 equivalent code quality generation, and not only that, today's model, code and data is all released completely open source!
Code-Feedback
is the released instruction-tuning dataset. Code-Feedback was created with three goals in mind: 1) Diverse and challenging real-world queries: The dataset should encompass a wide range of queries derived from real-world coding tasks, presenting both diversity and complexity. 2) Multi-turn dialogue structure: Code-Feedback is structured as multi-turn dialogues, incorporating two types of feedback: execution feedback, which includes outputs and diagnostics from compilers, and human feedback, consisting of additional guidance or instructions from users. 3) Interleaved text and code responses. To meet these criteria, the authors source data from 1) a variety of open-source datasets, and 2) coding challenges from LeetCode.
Open-source datasets
A total of 287k code queries are sampled from open-source datasets Magicoder, ShareGPT and Evol. These are filtered down to a high quality subset of 156k queries, using Qwen-72B as a complexity evaluator (1 to 5). I love that the filtering prompts are provided in the Appendix, because it gives us an opportunity to scrutinize them. First off, LLMs are poor at handling continuous ranges like the ones used here. The prompts do a really good job at relating the numeric scores to a highly descriptive label. Another great strategy is averaging the score between two templates, with slightly different templates. When I ran my own tests of continuous ranges I saw great benefit from zero-shot CoT and at first sight it seems like the authors have employed that as well, ending the prompt off with
...
Please give the score first then explain why.
but why is the score first, followed by the explanation? It seems like their actively trying to avoid CoT but still want the reasoning for debugging purposes?
Anyway, these 156k queries are turned into multi-turn dialogues using embedding similarity based packing and interaction simulation (gpt-3.5 + gpt-4).
LeetCode
is used to enrich the coding challenges. They amalg entries from the TACO dataset into multi-turn instances based on the similarity tags provided in TACO. Finally, they extend entires from the LeetCode dataset by aggregating diverse solutions to the same questions, specially ones that differ in language or space/time complexity. This yields 200 multi-round instances, showcasing alternative problem-solving approaches. To meet the goal #3, these solutions are intertwined with natural language explanations using GPT-4.
OpenCodeInterpreter
CodeLLama and DeepSeekCoder are the base models upon which Code-Feedback is applied. I am extremely bullish on DeepSeek. Their code models are great and their general 16B MoE looks amazing. Hopefully they release a bigger MoE in the near future, I expect it to outperform everything in the open space.
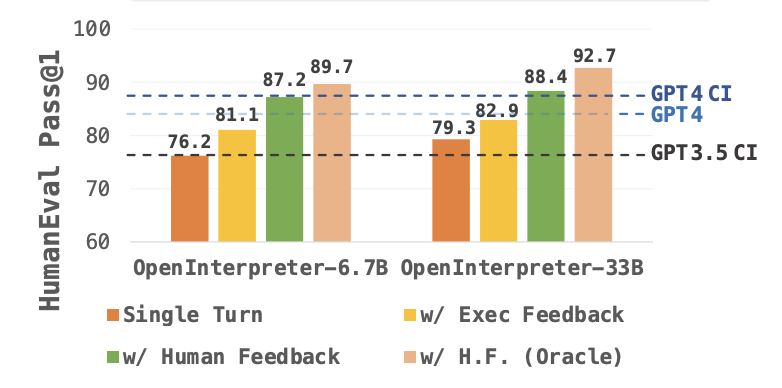
OCI achieves a respectable 83.2 on the combined HumanEval + MBPP test suite, surpassing all previous open source models. Note however that this result incorporates execution feedback. This is a slight improvement over the DeepSeekCoder Instruct model at 81.9. This means that we've finally got a model that surpasses the performance of GPT-3.5 CI but we're still a long way from GPT-4 with it's score of 90. This shouldn't be surprising; we're comparing a 34B model to what is most likely a 1.7T parameter model.