Reading Roundup
February 15, 2024
It's been a while, a lot going on right now and I've been coding more than reading recently. Given that it's been some time it felt appropriate to come back with a reading roundup of some things I've read recently that deserve both your and my attention.
World Model on Million-Length Video and Language with RingAttention
I've dabbled with in-context retrieval tests so when I saw this I figured I had to read the paper
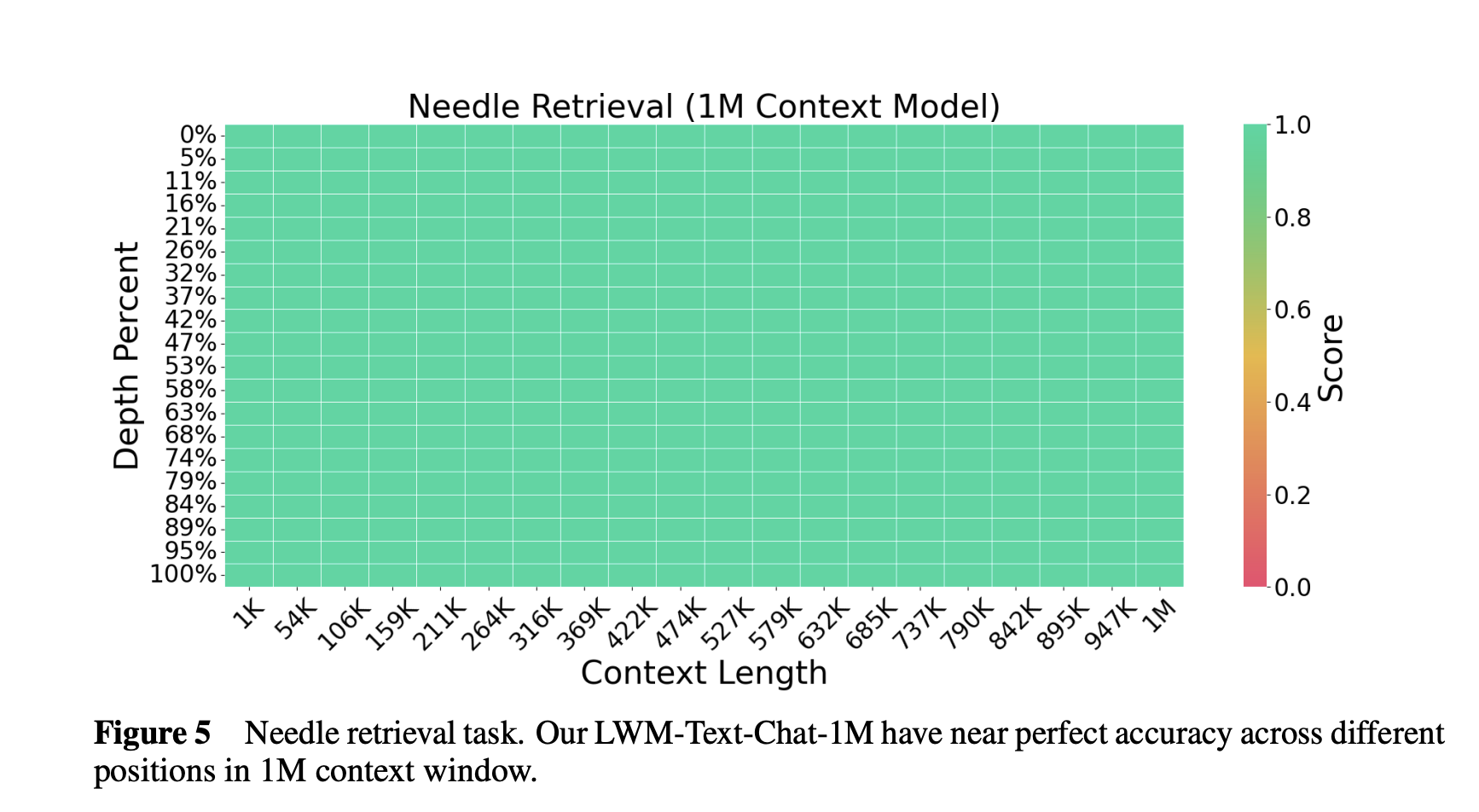
This paper explores building a long-context world model through extended context and multimodal training. The hypothesis is that current models lack in understanding of certain aspects of the world which are difficult to capture in texts. Thus, training on temporal structures in video sequences will help provide this missing information; long language sequences encode information that short sequence equivalents can not. To achieve this goal of learning from video sequences, the authors need a model capable of processing more than a million tokens per sequence and train it on a very large dataset. Their training is layed out in two stages:
Stage 1. The authors begin with the staple Llama 7B, which has a context window of 4096. Expanding context in base models requires addressing the challenges of extrapolating beyond trained sequence lengths (positional O.O.D) and the quadratic complexity of attention mechanisms. The prohibitive memory demands of long-document training due to attention were mitigated by integrating RingAttention with FlashAttention. Furthermore, to circumvent the computational complexity, the training progressively increased context sizes from 32K to 1M tokens, rather than starting directly at 1M tokens. Additionally, the authors employed RoPE base period scaling to tackle positional O.O.D in encodings, a technique first introduced in the CodeLLama paper.
Stage 2. This stage involved further fine-tuning of LWM 1M on joint video and language sequences. Input images of size are tokenized into discrete tokens. Videos are tokenized per frame and modalities are differentiated with special tokens. Training mirrored the progressive approach of Stage 1, starting with 1k context and gradually advancing to 1M tokens, excluding the RoPE base frequency scaling already applied in the first stage.
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models
In recent weeks, I have been highly enthusiastic about EQ-Bench, a benchmark developed by an independent researcher that exemplifies solid research deserving recognition. EQ-Bench proposes that emotional intelligence serves as an effective measure of general intelligence. Traditional methods for assessing human emotional understanding are challenging to adapt for Large Language Models (LLMs), leading to a gap in objective evaluation metrics. EQ-Bench addresses this by presenting scenarios with emotional dynamics and asking LLMs to assess the emotional intensity experienced by characters in these scenarios. This approach provides a nuanced understanding without necessitating subjective interpretations by evaluators, thereby avoiding the need for human intervention or LLM-based judging.
The benchmark involves GPT-4 generating 70 scenarios, with models assessing emotions based on a predefined template, rating emotional intensities on a scale from 0 to 10. The reference answers were established by the test creators to prevent model bias.
At the end of this dialogue, Jane would feel:
Surprised:
Confused:
Angry:
Forgiving:
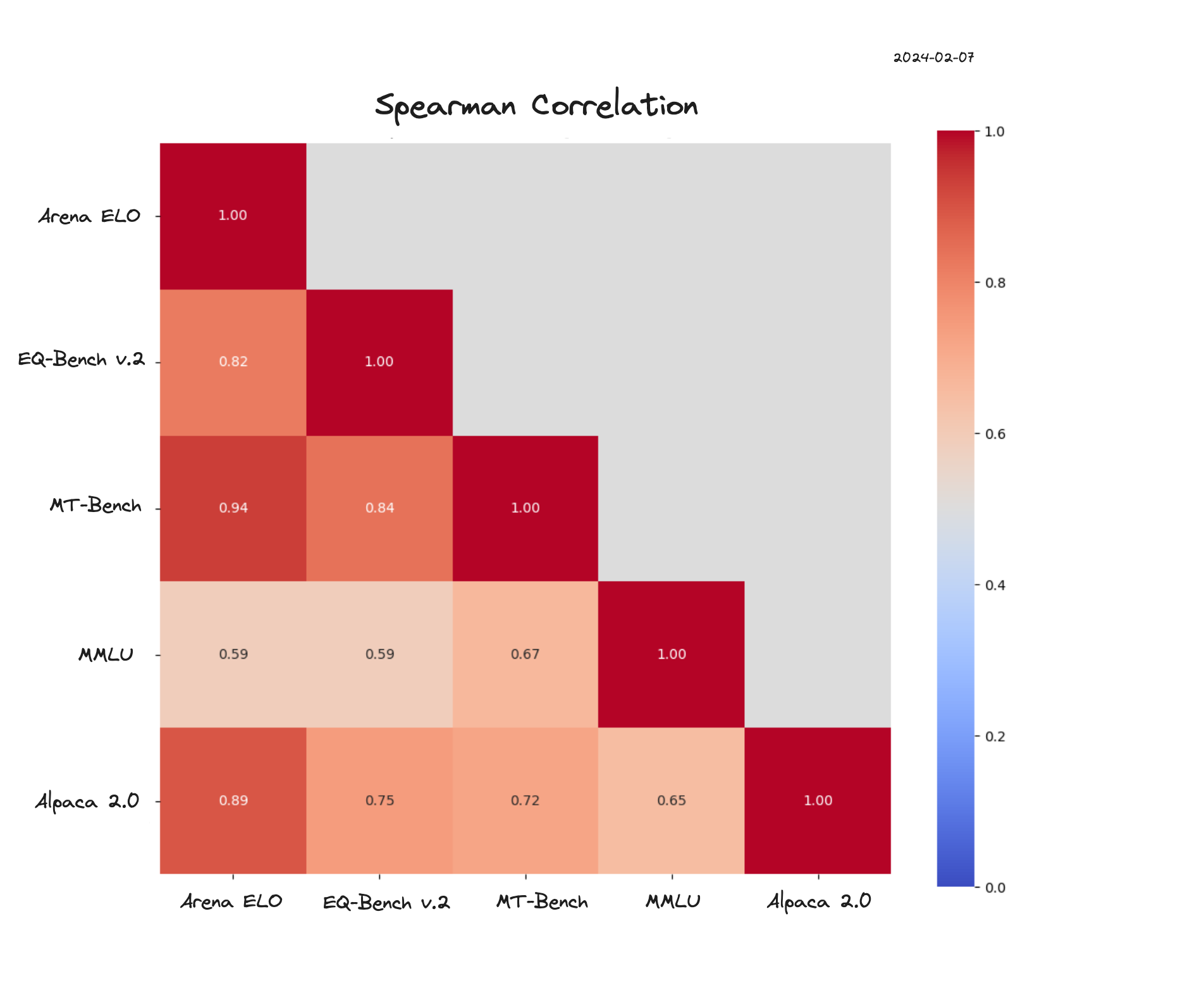
What stands out about EQ-Bench is its efficiency and accessibility, especially when compared to benchmarks like MT-Bench or AlpacaEval. With only 70 questions (extended to 170 in EQ Bench v2), it simplifies the evaluation process and eliminates the need for high-cost judge models like GPT-4. This accessibility is particularly beneficial for the open-source software community. To illustrate the benchmark's relevance, I have conducted correlation analyses between EQ-Bench and other leading evaluation methods.
Transformers Can Achieve Length Generalization But Not Robustly
Length generalization, defined as the ability to extrapolate from shorter training sequences to longer test ones is a significant challenge for language models. In a simple task such as numeric addition it has been well established that LLMs fail to perform when the number of digits exceeds that which exists in the training data. This limitation raises concerns if Transformers genuinely grasp the underlying algorithm for a given task or rather are merely resorting to superhuman levels of memorization. Before we dive deeper it's important to understand the different between task length generalization and context length generalization. As opposed to the LWM paper discussed above, here we are not talking about the ability to handle longer contexts than seen during the training process, but rather the ability to generalize a specific task beyond the length seen during training, where numeric addition is a great example of this. This paper finds that they are able to perform 100-digit decimal addition with more than 98% accuracy with a model trained up to only 40-digit addition.
Attempts at improving Transformer's length generalization ability primarly focus on two areas: positional encodings and optimizing data formats. To this end, the authors propose the following recipe:
- FIRE position encodings (Li et al., 2023): A type of Additive Relative Positional Encoding scheme that modifies the attention logits of each layer using a learned bias. The process is formalized as where is the bias matrix induced by FIRE.
- Randomized position encodings (Ruoss et al., 2023): Randomly sample encodings from a range exceeding test-time lengths while preserving the order. Transformers trained this way adapt to larger positional encodings, effectively eliminating OOD position encodings during testing.
- Reversed format: The reversed format makes it easier for the model to decompose the long computation to local, “markovian”, steps that depend only on the single previous step.
- Index hints (Zhou et al., 2023): For example, 42 + 39 = 81 is represented as 𝑎4𝑏2 + 𝑎3𝑏9 = 𝑎8𝑏1 during training and inference, enabling transformers to execute indexing via induction heads.
Unfortunately, the proposed recipe is quite intricate, and a clear step away from standard practices in language model training all while only tackling the problem of digit addition. The authors also reveal that the achieved generalization is fragile, being highly dependant on training order and random weight initialization. It's clear that we're still long ways away from task generalization and while it seems clear that the problem has strong correlations with positional encodings and data formats, a robust solution is not evident.
Gemini 1.5 Pro
Funny that as I was writing this post we had one of the biggest days in AI I can remember. Gemini 1.5 Pro and OpenAI Sora dropping on the same day. I don't have much to say about Sora except that it's fucking insane. Gemini 1.5 actually came with a technical report, albeit lacking of much interesting. They claim that 1.5 is a continuation of 1.0 but with a MoE Transformer architecture. I probably wouldn't even write anything about Gemini as I've been generally quite unimpressed with what they achieved, but... when they flaunt an almost perfect in-context retrieval up to 10M tokens, you're going to turn some heads.
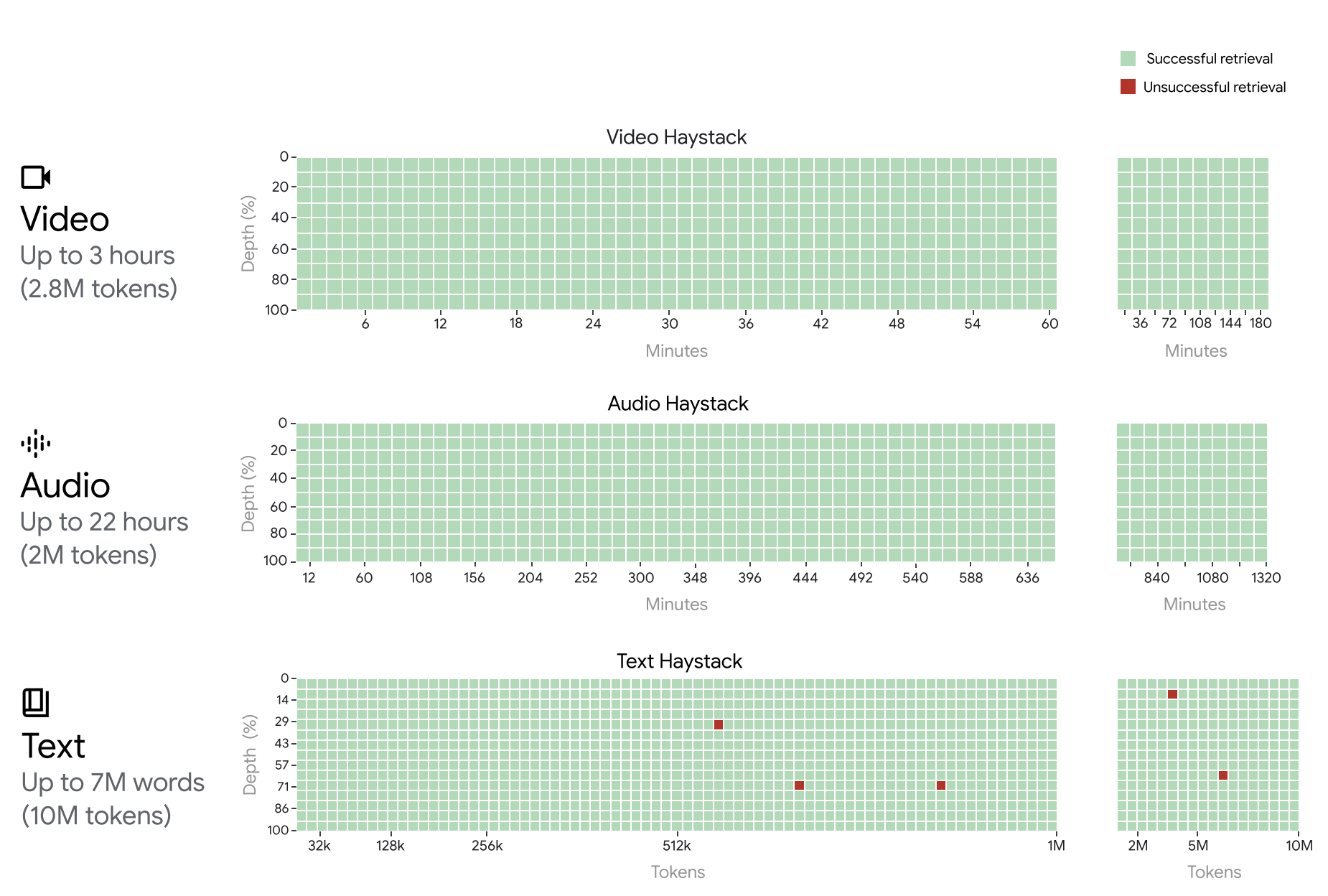
I was just taking about how impressed I was with LWM being able to handle a 1M context window, then Gemini drops this the day after with insane context ability. As per usual, the actual technical aspects of the report are, sparse to say the least. "trained on multiple 4096-chip pods", dataset includes data sourced across many different domains, including web documents and code, and incorporates image, audio, and video content., "A host of improvements made across nearly the entire model stack (architecture, data, optimization and systems) allows Gemini 1.5 Pro to achieve comparable quality to Gemini 1.0 Ultra". they're not saying anything :) can't be asked to read further at this point, it's just benchmark results and evaluations that don't really interest me.