Reading Roundup
January 4, 2024
Short format collection covering two papers I've just read.
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Fine-tuning and alignment is still a fragmented research space, the things that seem to work best (RLHF) require a substantial volume of human annotated data. There is an increasing interest in fine-tuning techniques that limit the amount of necessary human involvement, and instead effectively utilize the supervised data that we have. This paper explores a post SFT fine-tuning technique, Self-play Fine-Tuning (SPIN), to replace the likes of RLHF, based on self-play mechanisms popularized by AlphaGo, AlphaZero etc combined with the success of Generative Adversarial Networks (GAN).
In a typical GAN, we have two components: the Generator (G) and the Discriminator (D). The Generator is tasked with creating data that is indistinguishable from real data, while the Discriminator evaluates the generated data. Mathematically, this can be represented as a min-max problem:
In the context of this paper, this process can be seen as a two-player game: the main player, or the new LLM , seeks to discern between the responses of the opponent player and human-generated responses, while the opponent, or the old LLM , generates responses as similar as possible to those in the human-annotated SFT dataset. The new LLM is obtained by fine-tuning the old one to prefer responses from over , resulting in a distribution that is more aligned with . In the next iteration,the newly obtained LLM becomes the opponent for response generation, with the self-play process aiming for the LLM to eventually converge to = , so that the strongest possible LLM can no longer differentiate the responses generated by its previous version and those generated by the human.
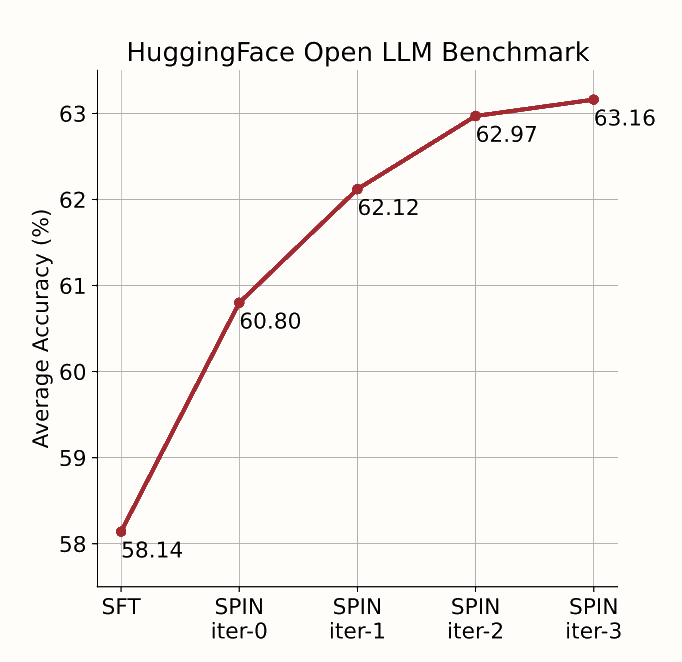
The process can be mathematically conceptualized as an iterative optimization problem, where the model's performance is continuously evaluated and enhanced based on its own outputs. The combination of self-play with the adversarial objective is what strikes me as brilliant here, I've considered applying self-play as a way to tune base models before but always struggled in defining an appropriate objective that leads to alignment. Here's the result of applying SPIN to zephyr-7b-sft-full, evaluated using the Huggingface Open LLM benchmark:
LLM Augmented LLMs: Expanding Capabilities through Composition
Alignment and fine-tuning have resulted in a wide array of highly capable domain-specific models. The general approach to extending a model's capabilities has involved further pre-training or efficiently fine-tuning a model using data from the desired task distribution. However, if there are already two orthogonally capable models, for example, one excelling in standard code generation but lacking in general logical reasoning and vice versa, is continuously training them really the most efficient method of merging these capabilities, or is there a better way? To answer this, the authors pose the question: Can we compose an anchor model with a domain-specific augmenting model to enable new capabilities?
Where previous methods of combining augmenting and anchor models, typically involving routing or merging, have fallen short, the CALM (Composition to Augment Language Models) framework innovates by introducing a mechanism we're already well familiar with: cross-attention. It makes a lot of sense when you hear it out loud, doesn't it? CALM introduces a smaller number of trainable parameters - a learned linear projection between the models into the same dimensional space and attention matrices in cross-attention - over both the augmenting and anchor models' intermediate layer representations. CALM successfully fuses the capabilities of the anchor and its augmenting models through just these additional parameters, freezing the base models and allowing this method to be backward compatible with any pre-trained models out there today! Here's an overview of CALM, with the anchor model in blue and the specialized augmenting model in red. The figure depicts three different examples.
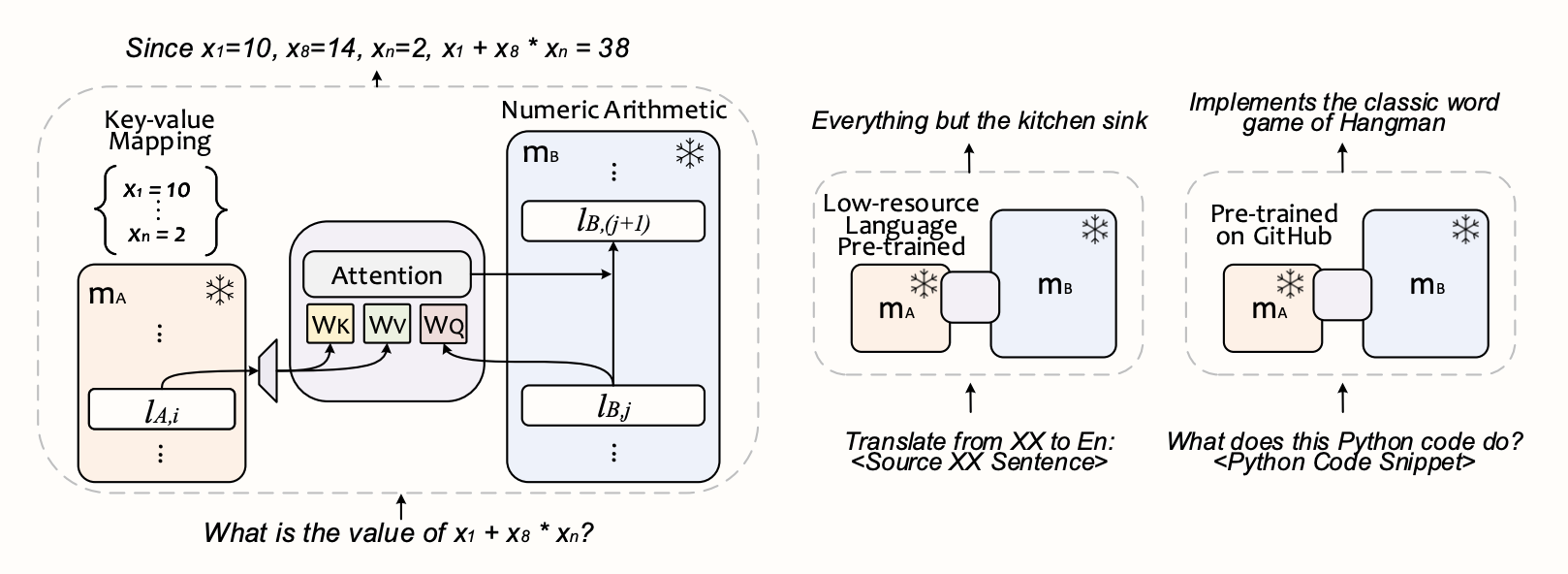
The essence of CALM lies in its ability to effectively combine different models to accomplish new, complex tasks that neither model could handle alone. This is achieved without compromising the individual capabilities of each model. CALM's methodology is not just a simple layer merging but a strategic composition that leverages the strengths of each model through these additional trainable parameters. However, with this kind of non-reductive merging, the number of parameters in the final product increases, and depending on the augmenting model(s), this increase can be substantial. Consequently, this affects the inference speeds of the model, which is not always desirable. This contrasts with LoRA, where the fine-tuned adapters can be merged into the original model, incurring no increase in complexity.