LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
Original paper · Jin et al 2024
Context windows of LLMs are generally restricted to the fixed length of the training data, when a base model is released it comes with a certain context length at that's it. Several attempts have been made to extend the base window, it's been discovered that fine-tuning models on longer contexts enables the models to extend beyond it's pretrained length. This can however be computationally expensive and as such methods to extend the window with no or minimal tuning have been proposed, a popular one being YaRN. All of these methods however, are based on the assumption that LLMs inherently lack the ability to handle longer context than their training data, but, is that actually true?
Why LLMs fail beyond their context window
The authors hypothesis that the inability to deal with extensive contexts has to do with out-of-distribution (O.O.D) issues related to the positional encoding scheme at use, which they term positional O.O.D issues. Specifically, in relative position encodings such as RoPE, this positional O.O.D relates to the previously unseen relative position between two tokens , defined as . Positional O.O.D refers to the case where the values seen during inference has not occurred in the training data; neural nets perform notoriously bad on O.O.D data. To address this, an intuitive and practical solution would be to remap the unseen relative positions to those encountered in the pre-training phase, thus extending the LLMs ability to handle longer contexts!
SelfExtend
SelfExtend is a novel approach proposed to address the positional Out-Of-Distribution (O.O.D) issue in Large Language Models (LLMs), specifically those using Rotary Positional Encoding (RoPE). This method employs a simple FLOOR operation to map unseen large relative positions to known positions encountered during pretraining. This process aligns with two key intuitions:
- In lengthy texts, exact positioning of words is not crucial for understanding the text; maintaining the relative order is sufficient.
- In natural language, the precise positioning of words in a small region is often unnecessary since words usually follow a set grammatical order.
SelfExtend is a plug-and-play method effective at the inference stage, allowing easy adoption by existing large language models. It has been tested with popular LLMs like Llama-2, Mistral, and SOLAR across various tasks, demonstrating significant improvements in handling long contexts and even outperforming fine-tuning-based methods in some cases.
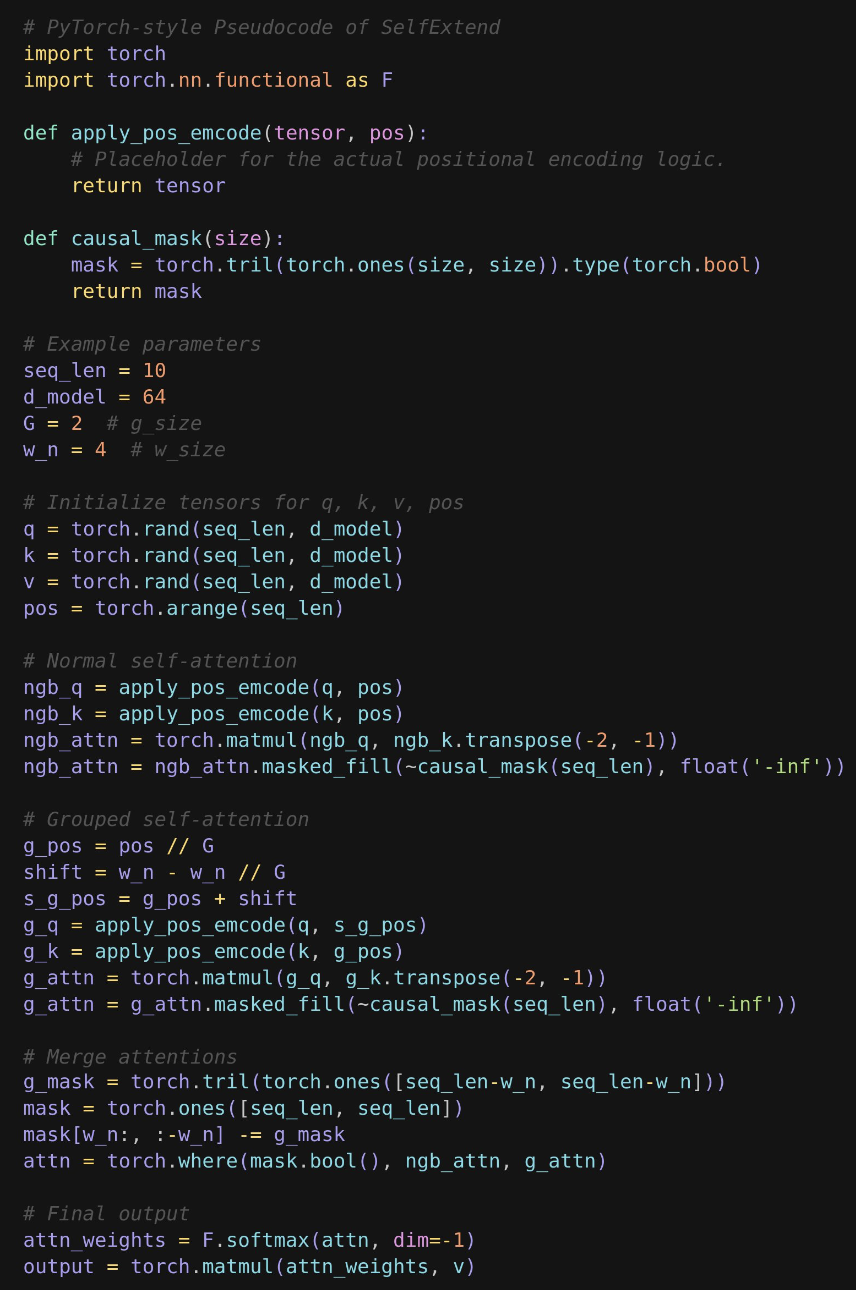
Below is an example implementation, illustrating how easy it is to plug SelfExtend into any LLM. Note that the users coin SelfExtend based attention as grouped attention
Performance evaluation
The performance of SelfExtend was thoroughly evaluated using three types of tasks: language modeling, synthetic long context tasks, and real-world long context tasks. The results were impressive:
Language Modelling
For language modeling, the performance was tested using the PG19 dataset containing long books. SelfExtend successfully extended the context window lengths of Llama-2 and Mistral beyond their original lengths, maintaining low perplexity (PPL) out of the pretraining context window. This showed that SelfExtend could effectively handle longer contexts without the performance degradation typically seen in LLMs without context window extension.
Long Context Tasks
In the realm of real long context tasks, evaluations were conducted using benchmarks like Longbench and L-Eval. SelfExtend demonstrated significant performance boosts across various datasets and models compared to their counterparts without extension. For instance, the context window of Mistral-7B was successfully extended, showing substantial improvements in long context abilities. SOLAR-10.7B also saw marked performance improvements with SelfExtend. These results were particularly noteworthy because SelfExtend doesn't require fine-tuning or additional training, yet it achieved comparable or even superior performance to methods that do.
What's key here is that this simple adjustment, which only requires a few lines of code in the Attention Block, massively improves a models long context capabilities, while upholding standard "in-context" benchmarks and short context abilities.