Mixture of Experts
Original paper · HuggingFace et al 2023
Mixture of Experts (MoE) are the flavor of the week following Mistral's release of Mixtral 7Bx8. Mistral are killing it at the moment, love their style; dropping a torrent link, letting the results speak for themselves. The contrast to Google's announcement of Gemini is hilarious, and it makes sense, Mistral is never going to appear more flashy or have the budget for a huge announcement ceremony, instead they entertain the 90's hacker vibe. Anyway as I was saying, Mixture of Experts are in vouge right now, but they are hardly a new discovery so today I'd like briefly overview their history and hopefully arrive at an understanding for their prevalence in modern LLMs.
Mixture of Experts - A brief history
MoE's can be traced back to the early 90's with a paper from none other than one of the Godfathers of Deep Learning Geoffrey Hinton, Adaptive Mixtures of Local Experts. The original idea was akin to ensemble learning; a system composed of separate networks, each experts in a different subset of the training data. The experts where chosen based on a gating network (typically a linear layer), and these gates are trained together with the expert networks.
As the deep learning revolution took off in the 10's, a couple of important advancements came to MoEs. In Learning Factored Representations in a Deep Mixture of Experts, the authors present MoE layers as a small part of a larger multilayer network. Previously, MoEs had comprised the entire system, but now they simply became a part of larger networks enabling MoE models to be both large and effective. People also realized that instead of we can dynamically activate or deactivate components based on the input token, allowing models to scale without impairing inference speeds 1 2. This work culminated in the foundation of modern MoEs, a paper again co-authored by Geoffrey Hinton, Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. As the title suggests, this paper introduced a Sparsely-Gated Mixture of Experts layer. These layers would consist of thousands of feed-forward sub-networks with a gating network that determines a sparse combination of the experts to be used for each token. The idea of sparsity is akin to conditional computation, in a dense model all the parameters would be used for all the inputs, but sparsity (or conditional computation) as I explained earlier allows us to only run parts of the whole system. If a model is trained with N experts this schematic allows the users to choose how many M << N experts they want use at the time depending on their computational resources.
Load Balancing
When training a model with MoE layers it is common to add noise to the gating mechanism to avoid expert occlusion. As one might imagine, it is common for the gating network to converge to mostly activate a subset of the total number of experts, making the whole concept of MoEs less efficient. This problem is circular as favored experts are trained quicker and hence selected more. In addition to noise, an auxiliary loss is added to encourage giving all experts a roughly equal number of training examples.
Google was one the first to blend large scale Transformers with MoEs in a framework they call GShard. GShard replaced every other FFN layer with a MoE layer using top-2 gating. To maintain a balanced load and efficiency at scale, GShard introduced two additional load balancing techniques:
- Random routing. The top expert is always picked but the second expert is sampled according to the gating weight probabilities.
- Expert capacity. A threshold for how many tokens can be processed by one expert. If both experts are at capacity, the token is considered overflowed and is sent to the next layer via a skip connection.
Mixtral
Mixtral uses concepts inspired by the Switch Transformer. It has a similar architecture as Mistral 7B with the difference that each Transformer Block replaces the FFN with a Switch Transformer block. Below is an illustration from the Switch Transformer paper:
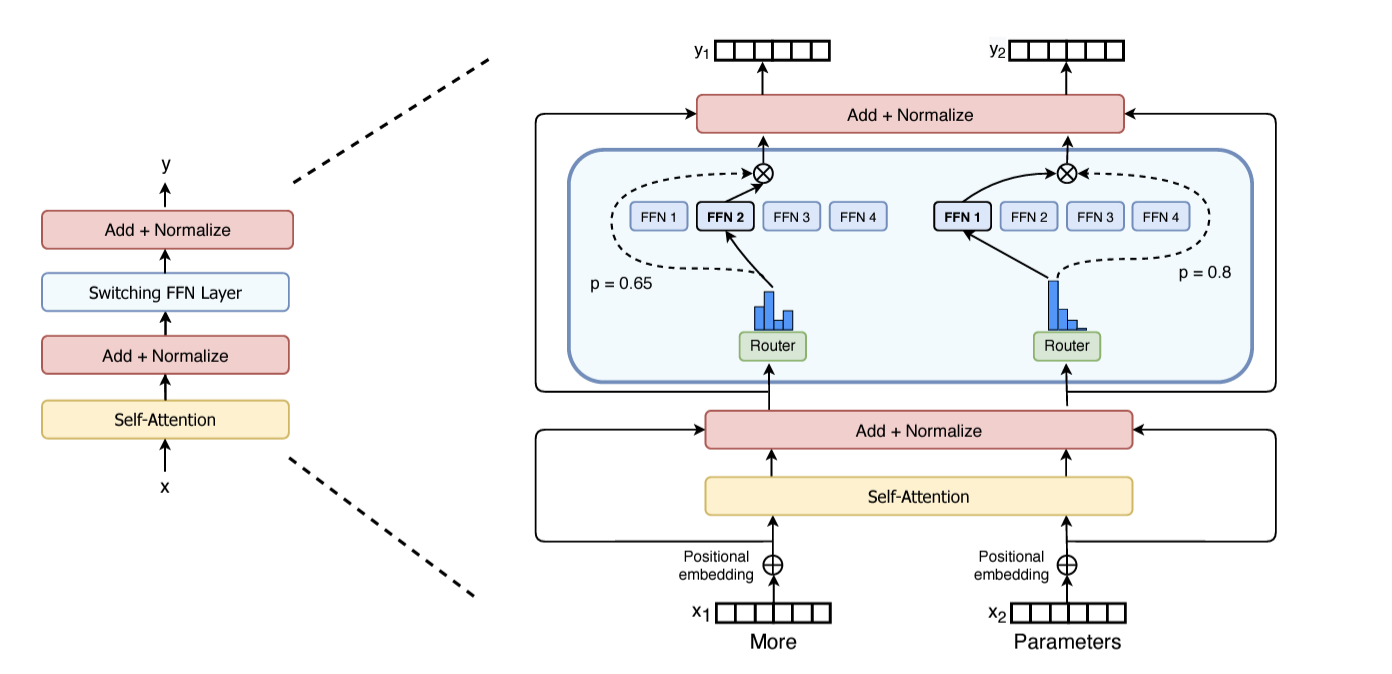
For every token, at each layer, a router network (gate) selects two experts to process the current state and combine the outputs. Mixtral uses 8 experts with top-2 gating. Even though each token only sees two experts, the selected expert can be different at each timestep. In practice, this means that Mixtral decodes at the speed of a 12B model, while having access to 45B parameters. The requirements to run this model are still quite hefty, you are looking at upwards of 90GB in memory but fortunately quantized versions of Mixtral have already been released and are available through popular frameworks such as llama.cpp, vLLM and HF Transformers. MoE as a architecture is interesting because of how you handle the experts in terms of batching, data parallelism and model parallelism.