ConvNets Match Vision Transformers at Scale
Original paper · Smith et al 2023
"Our work reinforces the bitter lesson. The most important factors determining the performance of a sensibly designed model are the compute and data available for training". This observation is neither novel nor surprising for many in the deep learning community. Over time, the common consensus has consistently reiterated: compute is paramount. Regardless of the particular architecture in use, it's the scalability that often determines the real-world performance of a model.
The Rise of Vision Transformers
Over the last few years, Vision Transformers have catapulted into the limelight, causing a significant paradigm shift within the computer vision community. Previously, the emphasis was on evaluating the performance of randomly initialized networks. However, the trend has now tilted towards networks pre-trained on massive, general-purpose datasets.
There's a prevailing notion that while ConvNets may be effective for small to moderately sized datasets, they somehow lose their competitive edge when compared to Vision Transformers, especially when the latter has access to colossal web-scale datasets. But is this assumption accurate?
Google DeepMind's Revelations
Recent findings from the researchers at Google DeepMind challenge this popular belief. Their studies demonstrated that by scaling state-of-the-art convolutional architectures, like NFNet, one can observe a log-log scaling correlation between validation loss and available compute resources. More importantly, such scaled ConvNets can match the performance of pre-trained Vision Transformers within comparable budget constraints.
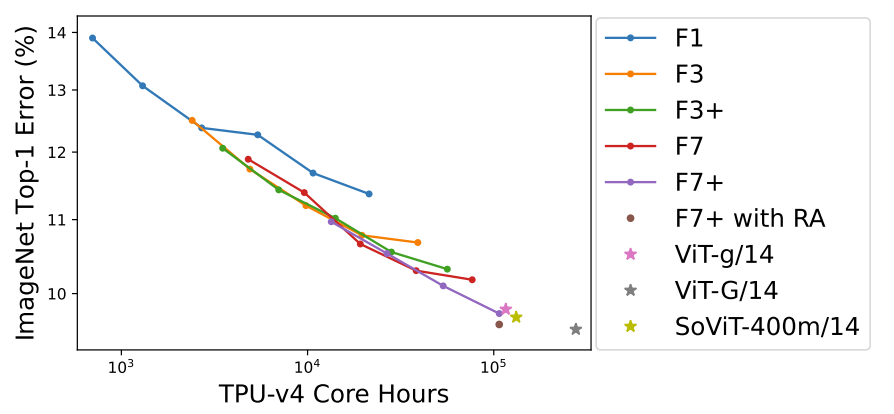
The figure aptly captures this revelation, illustrating that in spite of the marked architectural differences, the performance of pre-trained NFNets at scale closely mirrors that of pre-trained Vision Transformers.
Concluding Thoughts
While the aforementioned findings are groundbreaking, it's also essential to recognize that model architecture's relevance isn't limited to merely computational efficiency or dataset size. The choice between ConvNets and Vision Transformers might pivot depending on the specific use-case at hand.
For instance, Vision Transformers have showcased their versatility and efficacy in multi-modal scenarios. Whether it's robotic learning, image-text pairing, or other interdisciplinary tasks, ViTs have carved a niche for themselves.