VIMA: General Robot Manipulation with Multimodal Prompts
Original paper · Jiang et al 2022
The notion of instructing robots using natural language isn't new, but achieving such interaction remains a quest. Given the strides in task consolidation within NLP and Computer Vision domains, the authors of VIMA probe the feasibility of extending a similar expressive and intuitive interface to a general-purpose robot. They envision a robot foundational model capable of interpreting multimodal input and exhibiting zero-shot task generalization.
Unifying the IO interface
Task specification emerges as a pivotal yet unresolved concern in robot learning. Historically, distinct tasks necessitated unique policy architectures, objective functions, data pipelines, and training regimes, culminating in compartmentalized robot systems. VIMA, however, introduces a unified multimodal prompt interface to describe a gamut of tasks, capitalizing on the prowess of large transformer models. Formally, a multimodal prompt of length is defined as a ordered sequence of texts and images where . A compelling visualization in the paper elucidates this notion further.
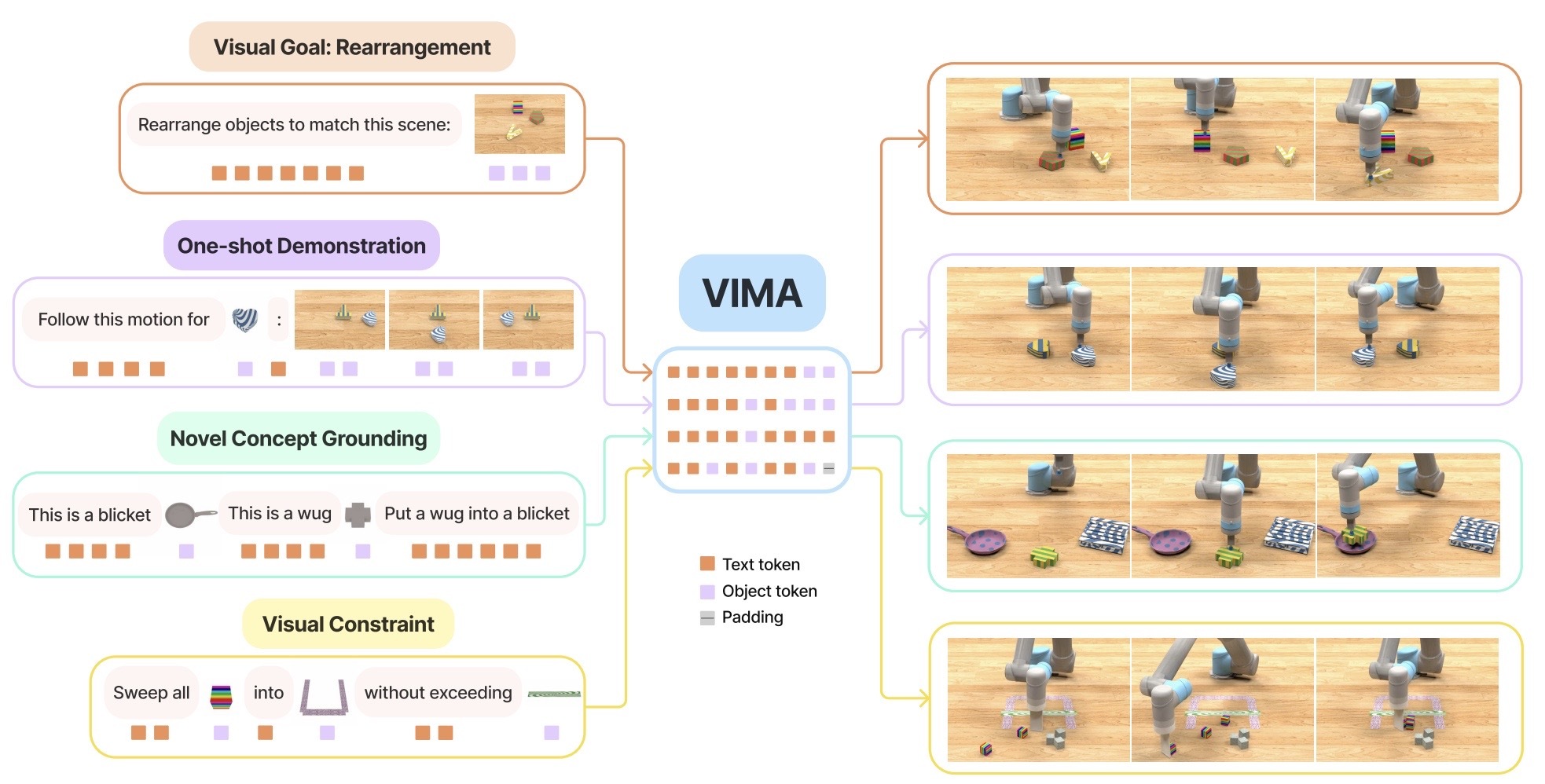
Visuomotor Attention Agent
There exist no prior method that works out of the box with multimodal prompts as input. Hence, the authors propose their own robot agent, VIMA, with a transformer encoder-decoder architecture and object-centric design. VIMA learns a robot policy where denotes the history of observation and actions at each interaction step. The amalgamation of encoded multimodal prompt and encoded history via a controller—a causal transformer decoder with alternating self and cross-attention layers—facilitates the prediction of motor commands conditioned on prompts and interaction history.
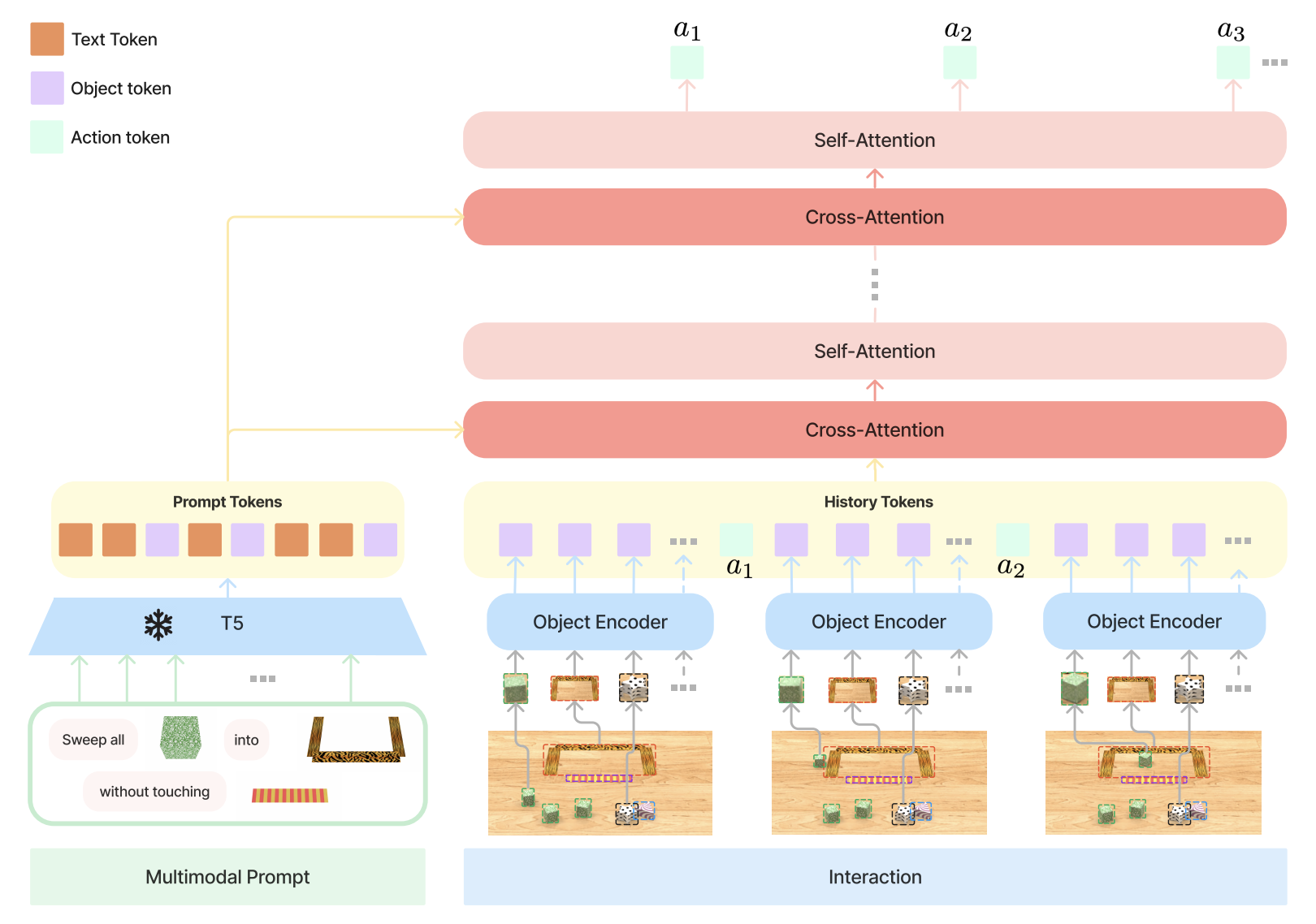
Notably, an observation is epitomized by multiple object tokens, diverging from the conventional single image token approach. VIMA accentuates object-centric representations, deriving tokens from bounding box coordinates alongside cropped RGB patches.
Tokenizing the input
The input ensemble comprises text, individual object images, and scene images. Text input undergoes tokenization using the pre-trained T5 tokenizer and word embeddings. Scene images see object extraction through Mask R-CNN, followed by encoding via a bounding box encoder + ViT. Conversely, single object images are encoded akin to scene images albeit with a dummy bounding box, culminating in a sequence of intertwined textual and visual tokens.
Robot Controller
The robot controller is arguably the linchpin of VIMA. It tackles the daunting task of engineering a pertinent conditioning mechanism for robot policy learning. How do we generate actions that adhere with the prompt and trajectory? The controller, inspired by the classical transformer encoder-decoder architecture, employs cross-attention layers to compute key and value sequences from the prompt and queries from the trajectory history. Each layer then generates an output sequence conditioned on the prompt and the trajectory history sequence . This solution is strikingly satisfying! The controller (decoder) consists of alternating cross-attention and self-attention layers. Six independent heads are use to decode the predicted action token into discrete actions (two for xy coordinate and four for rotation represented in quaternion). These discrete actions are then integrated and mapped to continuous actions through affine transformation.
Evaluation
VIMA's performance exhibits a commendable consistency across diverse model capacities, ranging from 2M to 200M parameters. Nonetheless, a pronounced dependency on the imitation learning dataset is observed, with a noticeable performance dip at 0.1%, 1%, and 10% of the full dataset size. A suite of ablation studies, exploring visual tokenizers, prompt conditioning, prompt encoding, and policy robustness, further enrich the evaluation narrative. The paper is a treasure trove of insights and comparisons for those delving deeper into this domain.