Superhuman AI for multiplayer poker
Original paper · Brown et al 2019
Pluribus achieves superhuman performance in no-limit Texas Hold'em poker, the most commonly played poker format in the world. Adding to the list of previously inconceivable feats of AI.
The nash equilibrium
AI systems have reached superhuman performance in games such as checkers, chess, two-player limit poker and Go. All of these games fall under the two-player zero-sum category of games, a special class of games in which the Nash equilibria has an extremely useful property: Any player who chooses to use a Nash equilibrium is guaranteed to not lose in expectation no matter what the opponent does. In other words, a Nash equilibrium strategy is unbeatable in a two-player zero-sum game. The AI systems developed, utilize this guarantee by approximating a Nash equilibrium strategy, rather than by, for example, trying to detect and exploit weaknesses in the opponent.
Although a Nash equilibrium strategy is guaranteed to exist in any finite game, efficient algorithms for finding one are only proven to exist for special classes of games, among which two-player zero-sum games are the most prominent. When more players are introduced, the whole concept of Nash equilibrium falters. Not only do we lack theory in finding the equilibrium, or even approximating it, it is not clear that playing such an equilibrium strategy would be wise. In two-player zero-sum games, players can independently compute and select Nash equilibria, and be guaranteed that the list of strategies is still a Nash equilibrium. We are fairly certain this is not the case for multiple player games. Given the shortcomings of Nash equilibria outside of two-player zero-sum games, and the lack of theoretical alternatives to overcome them a question arises of how one should approach games such as six-player poker. Pluribus is not grounded in a game-theoretic solution concept, but rather in a empirical devotion to create an AI that consistently defeats human opponents.
Pluribus
Self-play has been empirically proven to generate powerful game AIs in two-player zero-sum games such as backgammon, Dota 2, StarCraft 2, Chess, and the list goes on. Although the exact algorithms used vary widely, the underlying principles have remained the same. Pluribus uses self-play to produce a strategy for the entire game offline, referred to as the blueprint strategy. During online play, Pluribus uses the blueprint as a initial search tree, improving on and discovering better strategies in real time.
Self play
The blueprint strategy in Pluribus was computed using Monte Carlo Counterfactual Regret Minimization (MCCRF), which is reminiscent of the Monte Carlo search used in AlphaZero. The strategy for each player is initialized as random; MCCFR simulates a hand of poker based on everyone's current strategy and designates one player as the traverses whose strategy is to be updated. A iteration is illustrated in the figure below
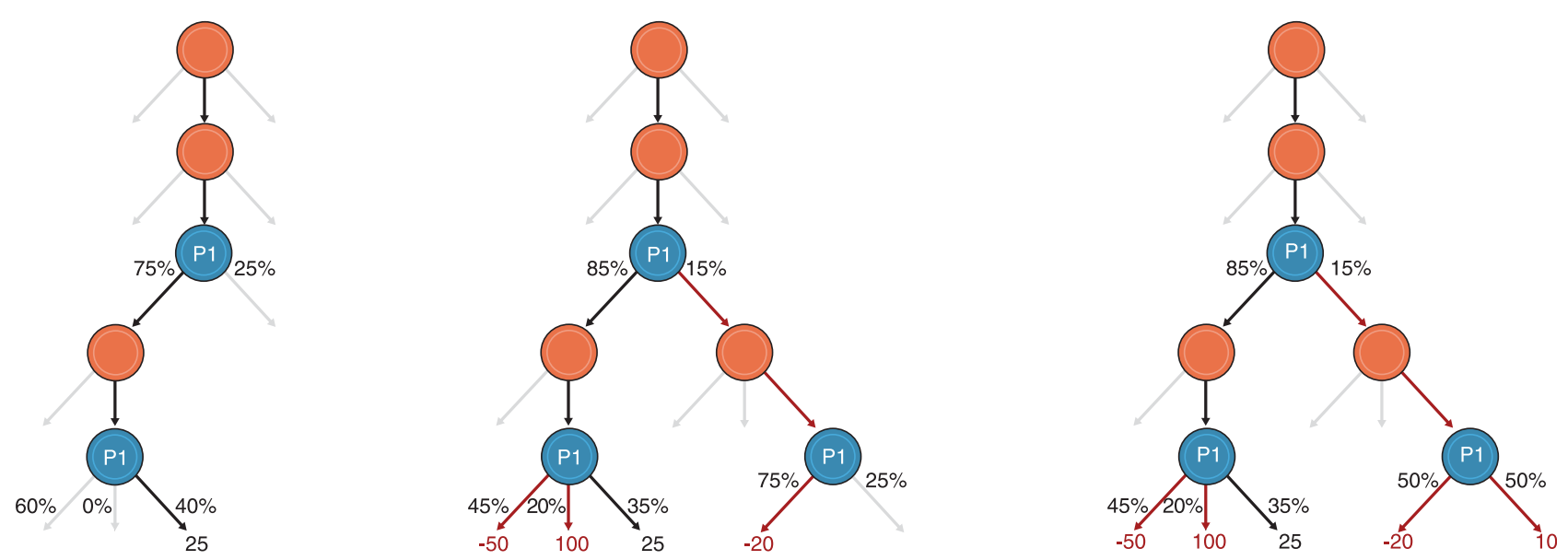
is traversing the game tree. (Left) The game is simulated until an outcome is reached, using the current known(!) strategy for each player. (Middle) For each decision point encounter in the left panel, explores each other action that could have taken and plays out a simulation to the end of the game. The difference in outcome between each decision point is added to the counterfactual regret for that action. Counterfactual regret represents how much the traverser regrets not having chosen that action in previous iterations. (Right) explores each other action that could have taken at every new decision point encountered in the middle panel, and updates its strategy at those hypothetical decision points. This process repeats until no new decision points are encountered; the traverser's strategy is updated according to the counterfactual regret of actions.
The blueprint strategy for Pluribus was computed in only 8 days, on a 64-core server for a total of 12,400 CPU core hours. This in sharp contrast to all recent superhuman AI's from DeepMind, OpenAI, etc. The idea behind the blueprint strategy is to allow Pluribus to real-time search on a high-end workstation, as opposed to creating the most fine-grained strategy before hand. The compressed form of the blueprint strategy takes no more than 128GB of memory.
Depth-limited search
Pluribus only plays according to the blueprint strategy in the first of four betting rounds, where the number of decision points is small enough to approximate / abstract. After the first round, Pluribus conducts real-time search to determine a better, finer-grained strategy for the current situation it is in. Real-time search has been necessary for achieving superhuman performance in many perfect-information games. For example, in chess AIs commonly look some number of moves ahead until a leaf node is reached at the depth limit of the algorithm's lookahead. An evaluation function then estimates the value of the board state at that leaf node if both players were to play a Nash equilibrium from that point forward. An AI that can accurately calculate the value of every lead node, can also choose the optimal next move every time.
Unfortunately, this kind of search is fundamentally broken when applied to imperfect-information games because lead nodes do not have fixed values. To combat this, Pluribus assumes that each player may choose between different strategies to play for the remainder of the game when a leaf node is reached, rather than assuming that all players place according to a single fixed strategy (which results in the leaf nodes having a single fixed value). The authors propose that the continuation strategy should be the precomputed blueprint strategy along with modified versions biased towards folding, calling, and raising, totalling .
When playing, Plubibus runs on two Intel Haswell E5-2695 v3 CPUs and uses less than 128GB of memory. For comparison, AlphaGo used 1920 CPUs and 280 GPUs for real time search. On average, Pluribus plays at a rate of 20s per hand when playing against copies of itself. This is roughly twice as fast as professional humans play.