Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Original paper · Smith et al 2021
The LLM with a name straight out of a Transformer movie brought to you by the folks at Microsoft and NVIDIA. I don't think I've covered any large scale LLMs from either Microsoft or NVIDIA before but they've both been in the frontline of the LLM race for the past few years. The Megatron-Turing NLG (MT-NLG) stands as the next-generation development, following Microsoft's Turing NLG 17B model. Upon its release in early 2020, the latter was recognized as the most expansive language model available. MT-NLG has since claimed its position as the premier monolithic language model, a feat achieved through an intensive collaboration between Microsoft's DeepSpeed and NVIDIA's Megatron-LM—both esteemed optimization libraries dedicated to efficient deep learning training. It's clear that the authors of this paper chose to push the boundaries of large scale models through innovations in training pipelines and improvement in optimization efficiency and stability. My understanding is that the model-parallel architectures presented in this paper were highly influential for modern LLM training so I'm really excited to learn more.
Challenges
To begin with the authors pass through a number of challenges that exist in the training pipelines. It's clear that there is enough available compute to train models in the trillion parameter range, but exploiting this availability requires memory and compute-efficient strategies for parallelizing thousands of GPUs. For example, given the model and training configuration for MT-NLG (530B), the aggregated activation memory required is estimated to 16.9 terabytes. Fortunately, such memory requirements can by mitigated by splitting batches into micro-batches that are processed in sequence and their resulting gradients are accumulated before updating the model weights. This effectively means we can scale training batch size infinitely without increasing the peak resident activation memory. For compute efficiency large batch sizes are a great solution, but too large of a batch size can effect model quality and with 4000 GPUs a large batch size of 4000 still only allows for 1 batch per GPU. Before we move on I'd like to cover three topics that are relevant for understanding the motivation and solutions presented in this paper - data parallelism, model/pipeline parallelism and tensor parallelism.
Data parallelism
Data parallelism (DP) is a omnipresent technique applied in distributed deep learning. DP divides the global batch into mini-batches and divides them across multiple data-parallel workers. Each worker calculates its forward pass in parallel, communicating parameters, gradients and optimizer states as necessary. After synchronization the weights are updated. Classic DP is very memory inefficient as model and optimizers are replicated across all workers but the Zero Redundancy Optimizer (ZeRO) improves memory efficiency by partitioning the replicated data among the workers and communicating them when necessary. With this, DP can achieve near-perfect scaling at small scales but the communication cost of aggregating gradients can limit compute efficiency on systems with low communication bandwidth.
Model/pipeline parallelism
Pipeline parallelism (PP) introduces yet another batch division, this time splitting into micro-batches. First however, PP spreads the model layers across multiple GPUs introducing stages that can be computed in parallel. As one stage completes the forward pass for a micro-batch, the activation memory is communicated to the next stage in the pipeline. PP reduces memory proportionally to the number of pipeline stages, allowing model size to scale linearly with the number of workers. It also has the lowest communication overhead, only needing to communicate between the stages.
Tensor parallelism
In tensor parallelism (TP) each GPU processes only a slice of a tensor and aggregates the full tensor only for operations that require it. If we look at a computation in matrix form, its easy to see how the operation can be done in parallel, either across the row or column:
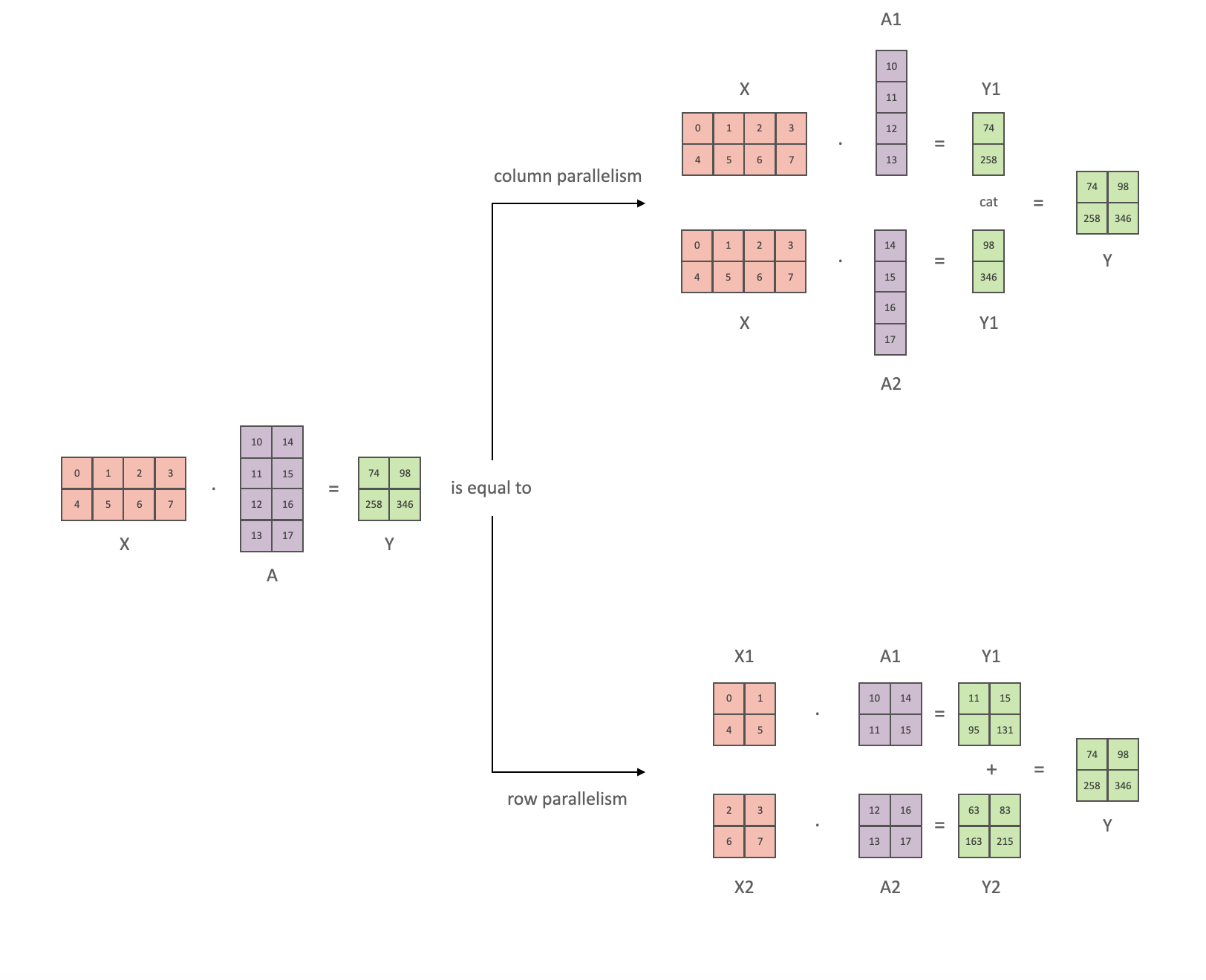
This allows us to update an MLP of arbitrary depth without needing to synchronize until the very end. Again, this method reduces the memory footprint of the model proportional to the number of workers. However, TP requires very fast communication and high bandwidth to be effective. It is not advised to perform TP across multiple worker nodes.
3D Parallelism with DeepSpeed and Megatron
While the existing parallelism techniques are good, non of them can individually address all the system challenges of training models with hundreds of billions of parameters. Instead, the authors introduce a 3D parallelism approach which combines data, model and tensor parallelism into a solution that is both compute and memory efficient enough for LLMs. At the time, DeepSpeed already provided an implementation of DP + PP meaning the authors could conveniently implement TP from Megatron into DeepSpeed creating a flexible 3D-parallelism stack.
Transformer blocks are divided into pipeline stages, and each stage is further divided via TP. DP is then used to scale to arbitrarily large number of GPUs. Tensor parallel workers are split across nodes, given that they have the highest communication requirements. When possible data parallel workers are placed in the same node, otherwise they are placed in nearby nodes. Pipeline parallelism has the lowest overhead so pipeline stages can be staged across nodes without a communication bottleneck.
Megatron-Turing NLG
The authors choose to train a single model with a very standard setup and configuration. Data is a combination of The Pile, CommonCrawl and Realnews which is pre-processed to remove duplication and ensure monolithic (english) text. The total training dataset consists of 339B tokens and MT-NLG is trained for 270B. The architecture used is a transformer decoder with 105 layers, 20480 hidden dimensions and 128 attention heads totalling 530B parameters. LR warmup is applied for the first 1B tokens followed by cosine decay. Batch size is increased gradually from 32 to 1920. Given what we now know from the Chinchilla paper, this model is heavily overparametrized for its 270B tokens, but I guess this is mostly about showing the power of DeepSpeed, funny thing to note anyway (this paper was released before Chinchilla). Anyway the model successfully outperformed a lot of SOTA models across a variety of NLP tasks at the time any showed that it really was possible to train such large models. More importantly, DeepSpeed provides perfect memory scaling - being able to train ~1.4B parameters per GPU (V100) and near perfect linear compute efficiency scaling. My understanding is that this had great consequences for subsequent models, enabling a more democratic model training environment.