BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Original paper · Devlin et al 2018
Authors introduce a new language representation mainly to be used for fine-tuning, where encoding is bidirectional meaning context is incorporated from both directions of a sentence. They use this to train models of size 110M - 340M parameters. To give a bit of background to pre-trained language representations the authors present the following three approaches:
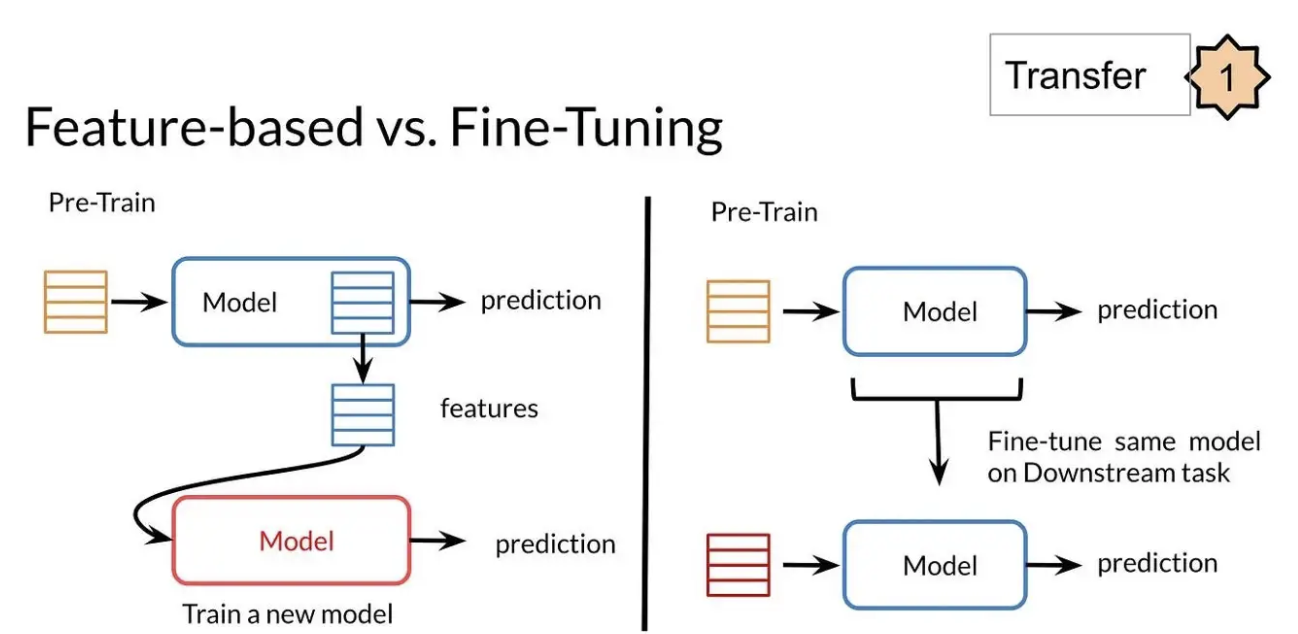
Unsupervised Feature-based approaches
Models trained to generate word embeddings have existed for a long time and this has been generalized to coarser granularities such as sentence embeddings and even paragraph embeddings. ELMo, being one of the most prominent word embedding models, extracts context sensitive features creating deeply contextualized embeddings that when integrated with task-specific architectures has shown to advance SOTA for several NLP benchmarks.
Unsupervised Fine-tuning approaches
Recent advancements in this field involve pre-training (on unlabeled text) sentence or document based encoders which produce contextual token representations and then fine-tuning these models for a supervised downstream task. Note, in this case the same pre-trained model is used, and most (or all) parameters are updated during fine-tuning as opposed to the feature based approach where a completely new model is trained using in part the pre-trained features.
Transfer Learning from Supervised Data
Finally, some work has shown success in effective transfer from supervised tasks with large datasets, such as natural language inference and machine translation. Computer vision research has also demonstrated the importance of transfer learning from large pre-trained models, where an effective recipe is to fine-tune models pre-trained with ImageNet.
BERT
There are two steps in the BERT framework: pre-training and fine-tuning. The model is pre-trained on unlabeled data over different pre-training tasks and then during fine-tuning it’s initialized with the pre-training parameters and all parameters are fine-tuned using labeled data for the specific task. Each downstream task has its own model. BERT uses WordPiece as a token embedder with a vocabulary of 30,000 tokens (remember a word embedder uses the training data to provide a fixed set of tokens that the model can use to represent text while requiring less memory than the normal english vocabulary).
Pre-training
BERT is trained using two different unsupervised tasks. First: In order to be able to train a deep bidirectional representation, without allowing each word to “see itself”, the authors propose a procedure called “masked LM” (MLM) which involves masking some percentage of the input tokens at random and then predicting those masked tokens. Interestingly, the authors note that this creates a mis-match between pre-training and fine-tuning as this masking doesn’t occur during fine-tuning, I’m unsure as to why this mismatch is important but the authors have gone out of their way to mitigate this by only replacing the tokens with a [MASK] token 80% of the time. Second: Downstream tasks such as question answering and NL inference requires understanding based on the relationship between two sentences. To model this the authors pre-train for a binarized next sentence prediction task, sentences A and B in each pre-training example are chosen such that 50% of the time sentence B actually follows A and the rest of the time it doesn’t.
Result
Results from BERT show an improvement over existing SOTA in 11 NLP tasks and show a strong correlation between increasing model size and improvement. These results stem from the fine-tuning approach, however, the feature-based approach, where fixed features are extracted from the pre-trained model, has certain advantages. Not all tasks are easily represented using the transformer encoder architectures and pre-computing expensive representations once to be used later on top of cheaper models has major computational benefits. Therefore the authors also present results where features are extracted from the activations between encoder layers. Best results come from BERT Large and when the representations from the top four hidden layers are concatenated. As a final note, BERT Large was, at the time, the largest model found in literature with over 300M parameters.