Improving Language Understanding by Generative Pre-Training
Original paper · Radford et al 2018
Authors from OpenAI present the first iteration of GPT, the original paper. Given the abundance of unlabelled text corpora but the scarcity of labeled data they propose a new approach consisting of generative pre-training of a language model on unlabelled data followed by discriminative fine-tuning on each specific task. It seems these authors were the first to apply a semi-supervised approach for language understanding where you first train on unlabeled data to learn a universal representation that will then transfer with little adaptation to downstream tasks trained on supervised data. Previous semi-supervised approaches include things such as word embeddings which are trained on unlabelled corpora to improve performance of downstream tasks, but they mainly transfer word-level information. There have been attempts to broaden the scope and embed phrase-level or even sentence level.
The model is built using a stack of transformer decoder blocks, 12 to be exact, with masked self attention heads (117M). The generative pre-training refers to the fact that unlabeled data is fed in as contiguous sequences of text (from corporas) and the model attempts to predict the next token repeatedly. The fine-tuning tasks then require some modification to the input as to avoid changing the architecture, shown in the figure below.
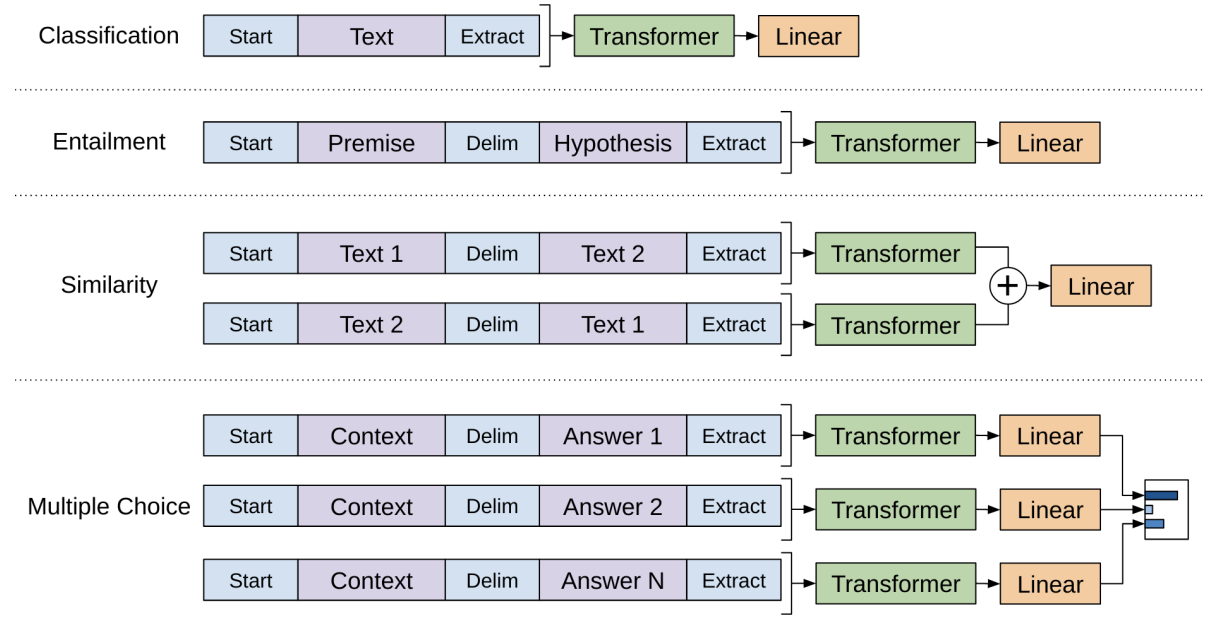
The authors perform an analysis of the achieved SOTA results and find a strong correlation between an increasing number of transformer layers and performance. To explain the strong effectiveness of the model they also perform a zero shot analysis meaning that they observe the performance of certain heuristics during the pre-training. To quote the authors “We observe the performance of these heuristics is stable and steadily increases over training suggesting that generative pre-training supports the learning of a wide variety of task relevant functionality”.