Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Original paper · Ioffe et al 2015
Training significantly deeper networks is complicated by the fact that the layer input distribution changes rapidly during training as the parameters of the previous layer change. This slows down training as it forces subsequent layers to adjust for the change in distribution. Ultimately this requires more careful weight initialization and a lower learning rate. This phenomenon is referred to as the internal covariate shift. The authors suggest a solution to this problem by making normalization a part of the network structure. Assuming a mini-batch size of m, the normalization is applied to each activation independently, thus resulting in a linear transformation
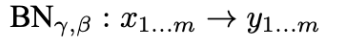
that is proven to make the optimization easier and allow higher learning rates with less careful initialization. It also seems to act as a regularizer.