Efficient Estimation of Word Representations in Vector Space
Original paper · Mikolov et al 2013
The authors propose two novel techniques to learn high-quality word embeddings on unlabeled datasets with billions of words. Previous architectures are trained on no more than a few hundred million words with a modest dimensionality of the word vectors between 50 - 100. They design a comprehensive test set for measuring both syntactic and semantic regularities. Computational complexity is compared by O = E * T * Q, where E is training epochs, T is training samples and Q is defined further for each model architecture.
Continuous Bag-of-Words is the first model which is trained by attempting to predict a word wt by building a log-linear classifier with four future words (wt+1 , … , wt+4) and four history words (wt-1 , … , wt-4) as input.
The second model, Continuous Skip-gram, is similar to CBoW but instead of predicting the current word based on the context, it tries to predict the context based on the current word. They use each word as input to a log-linear classifier and predict words within a certain range before and after the current word. Larger range implies a higher complexity.
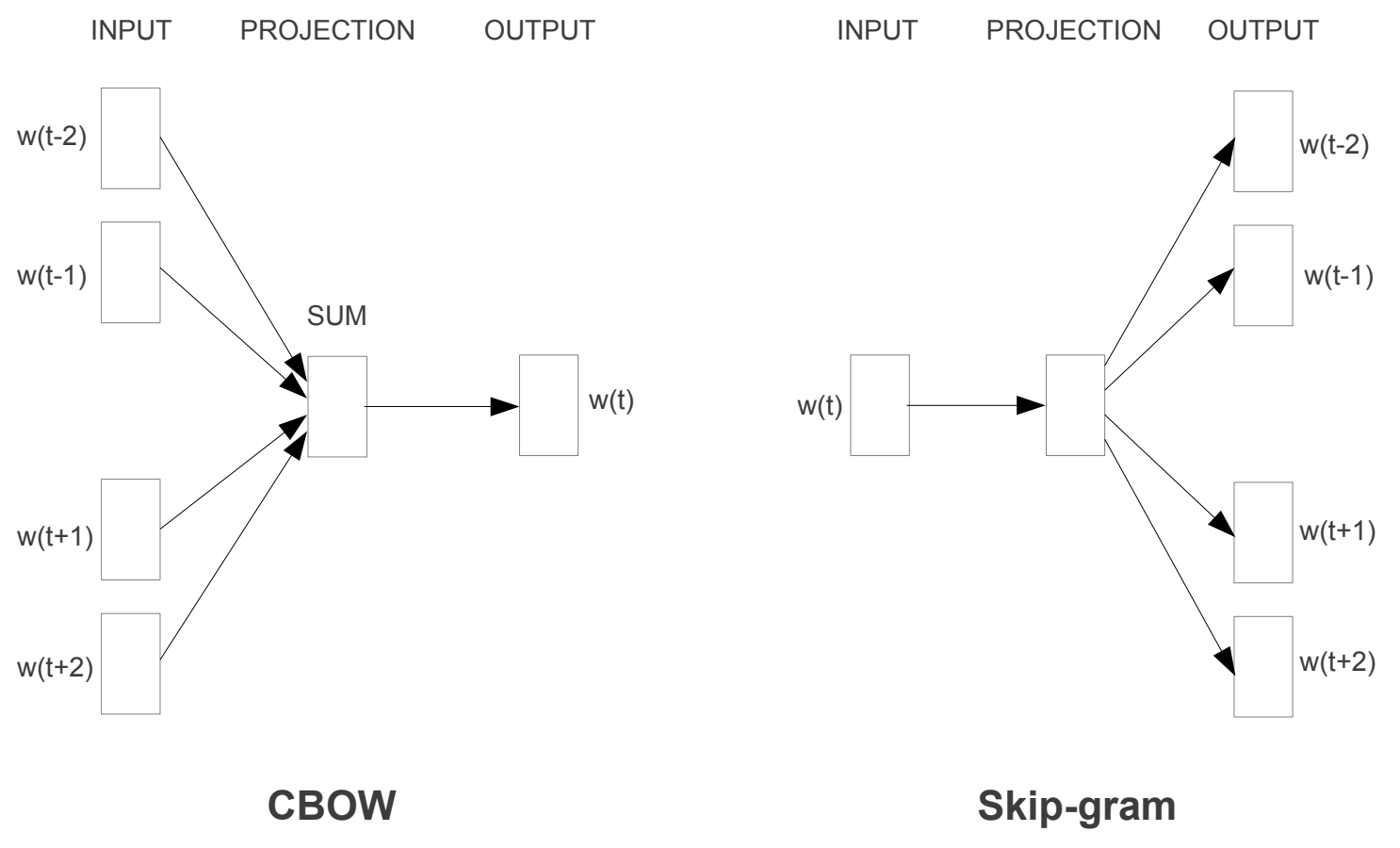
The results from this paper show that quality vector representations can be derived from very simple model architectures thanks to their low computational complexity and ability to train on large datasets. Using a distributed framework the authors claim that it should be possible to train CBow and Skip-gram on corpora with trillions of words. Learned representations that were especially interesting from this paper was the ability to show that vector(”King”) - vector(”Man”) + vector(”Woman”) results in a vector that is closest to the representation of vector(“Queen”).